基本概念
Q:什么是防火墙?
简单来说就是工作在 网络边缘 或者 主机边缘、根据事先定义好的规则对进出的数据报文进行检查和处理的模块。
因为工作位置的不同,原理的不同,虽然都是防火墙,但是可以按照类别进行划分。
位置划分:
- 对于工作在网络边缘的防火墙,我们叫它 网络防火墙,一般是硬件设备进行处理,也叫 硬件防火墙。
- 对于工作在主机/服务器边缘的防火墙,我们叫它 主机防火墙,一般是通过软件进行处理,也叫 软件防火墙。
原理划分:
- 包过滤防火墙:就是能够对数据包进行简单的过滤,比如说根据 源ip地址 和 目标ip地址 ,源端口和目标端口等等规则进行数据包过滤。常见的比如允许80端口的数据包放行,其他端口不允许。
- 应用层防火墙:主要是用来过滤应用层信息。
配置划分:
- 内核态防火墙
- 用户态防火墙
GNU/Linux 防火墙由两部分组成,netfilter 和 iptables(Centos 6 及以下的版本使用iptables,Centos 7/8/9 使用 firewalld )。netfilter 是基于内核的部分,管理员无法直接修改里面的内容,所以需要一个工具来修改里面的内容,也就是 iptables 或者 firewalld,两者结合才是完整的防火墙功能。
根据防火墙的定义,是需要预先定义好规则,即规则是防火墙最核心的内容,不管是哪种防火墙,都需要定义规则,去匹配相应的数据类型。所谓 防火墙规则,就是一种给防火墙筛选数据报文的方法。
GNU/Linux的规则有两种,即 默认规则 和 自定义规则。默认规则是最基本的规则,要么全部通过(开放),要么全部不通过(关闭),这在生产环境下肯定不适合。所以,我们需要在默认规则的基础上,再去定义大量的自定义规则,从而实现允许个别,拒绝所有,或者是允许全部,拒绝个别。
Q:自定义规则的匹配标准常见有哪些?
- IP头部,常见的源ip和目标ip
- TCP头部,常见的源端口和目标端口
- UDP头部,常见的源端口和目标端口
数据的走向
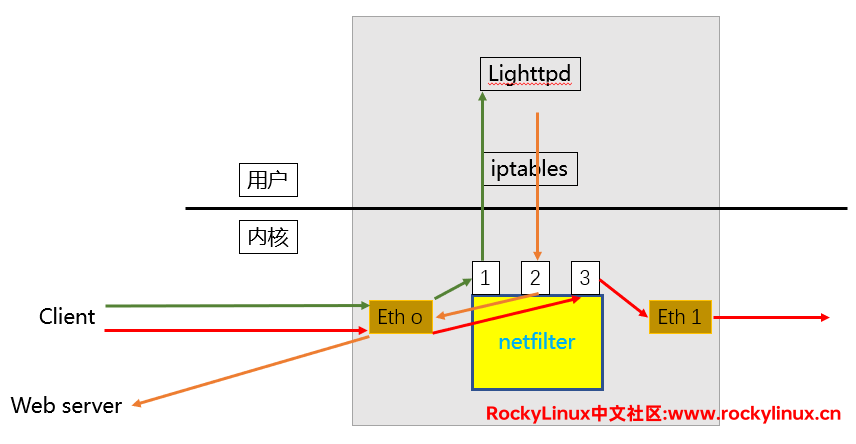
netfilter 提供了这么5个接口,管理员可以通过 iptables 在接口处配置规则,来实现数据包的过滤。
-
外部访问本地的程序
当客户端通过 Eth 0 网卡发送数据包,要判断是否是从本地应用响应还是从当前的主机做数据转发,具体看 TCP/IP 协议路由表。如果这个数据是要发送给本地的话,那么它的过程如 绿色线 那样,通过 1 位置(或者叫 1 接口)转发给本机相应的应用程序。
-
本地访问外部程序
当前主机的一个用户访问了外部的 web server,它的过程如 橘色线 那样,通过位置 2 访问 web server。2 位置也可以是响应的位置。
-
本地负责转发
外部 client 通过 Eth 0 向我当前的主机发送了数据包,该数据包并不是访问当前本机的应用程序,通过接口 3 ,把经过Eth 0 网卡的数据包转发和发送出去,过程如 红色线 所示。
Q:问题来了,如果我要拒绝某个客户端请求,是应该在请求的时候就拒绝,还是响应的时候拒绝?
1 位置和 2 位置都能实现,只不过1 位置设置规则的话,数据包到达应用程序之前就会被拦截掉。而如果是 2 位置,则该数据包经过了应用程序。从效率上来说,在 1 位置设置规则的效率更加地高。
Q:除了1、2、3位置,还有其他的位置(接口)吗?
有,4 和 5。一台主机有多块网卡时,我们可以将这台主机配置成一台路由,让这台主机依据逻辑地址进行寻址并转发数据。这台 GNU/Linux 主机必须开启两个功能——路由功能(Router)和网络地址转换功能(NAT)。
比如说有这样的一个环境,一个局域网 client 访问公网的 web server,经过网关(也叫默认路由)后,如果这个数据包不做任何的变化,web server则会把 源地址 作为 目标地址 来响应客户端,但是我们都知道,私有IP地址是不能直接在公网上使用和通信的,所以这个数据包出网关之后,通过 NAT 把 源地址 转变为 公网地址。
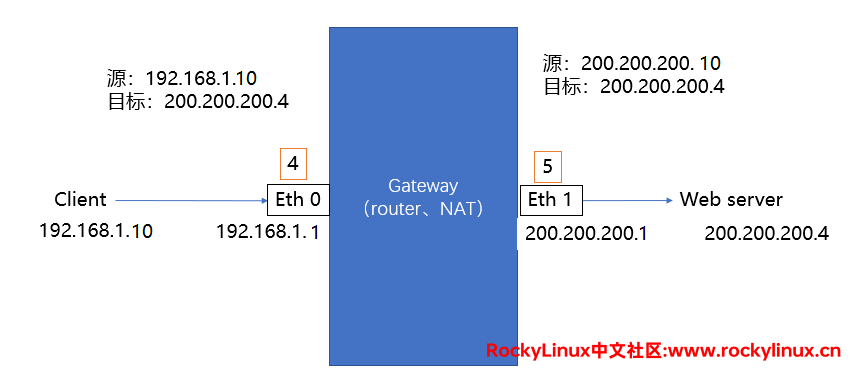
现在我们知道了这五个位置,说明如下:
- 1 位置,设置入站的防火墙规则,被称为 INPUT
- 2 位置,设置出站的防火墙规则,被称为 OUTPUT
- 3 位置,设置转发的防火墙规则,被称为 FORWARD
- 4 位置,路由转发之前的防火墙规则,被称为 PREROUTING
- 5 位置,做完路由转发之后的防火墙规则,被称为 POSTROUTING
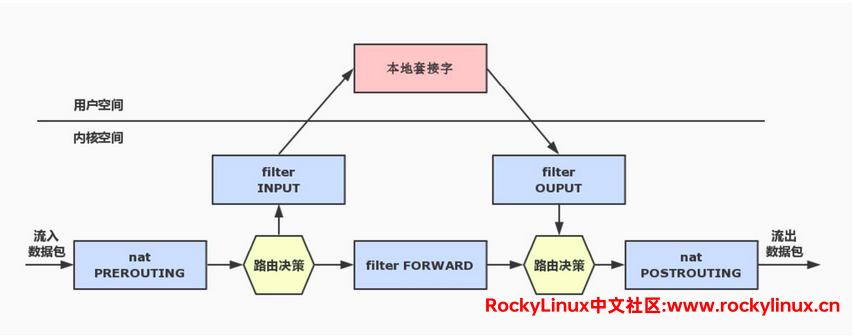
规则链
我们知道在一个位置可以设置多条规则,遵循 「自上而下」和 「匹配即停止」 。把该位置的多条规则首尾连接起来,就形成了一个链状结构,即 规则链,作用是承载防火墙规则。
- 如果是入站数据包,则是 PREROUTING链 —> INPUT链;
- 如果是出站数据包,则是 OUTPUT链 —> POSTROUTING链;
- 如果是转发数据包,则是 PREROUTING链 —> FORWARD链 —> POSTROUTING链
如下图所示:
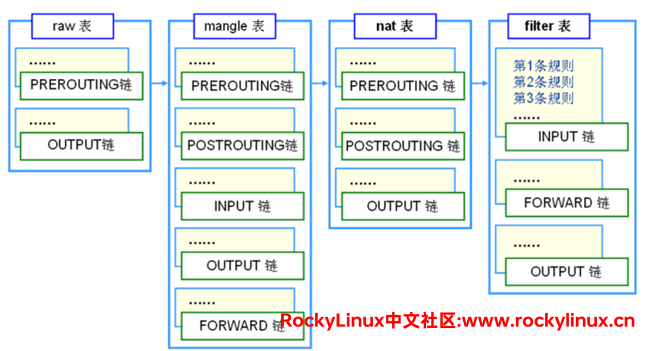
规则表
所谓规则表,就是根据规则链组合实现功能的不同而定义的表,就叫 规则表。
- raw 表:实现状态跟踪。包含 FREROUTING 和 OUTPUT
- mangle 表:标记,比如说给所有的数据包打标记,告诉数据包走哪条链路,或者标记数据包生存周期TTL等。包含INPUT、OUTPUT、FORWARD、PREROUTING、POSTROUTING
- nat 表:转换源ip地址、目标地址、源端口、目标端口等。包含OUTPUT、PREROUTING、POSTROUTING
- filter 表:数据包的过滤,顾名思义就是哪些数据包能通过防火墙。包含INPUT、OUTPUT、FORWARD
对于规则表来说,生效顺序依次是 raw表、mangle表、nat表、filter表。
我们常说的「四表五链」,它们之间的关系是这样的: