
题外话: 虽然很多同学已经掌握了 Kubernetes(K8S)的安装和配置技巧,但在实际公司业务场景的使用过程中,缺乏从服务和业务角度出发来系统性分析、排查和处理问题的有效方法。基于此,木子想着将自己八年左右使用 Kubernetes 的经验,以及在此过程中遇到的各种问题,通过写作来与大家分享,希望对各位读者有所帮助。
背景说明
最近发现 CEPH 的磁盘写入占用很大,去到 50+MiB/s(如下图所示),对于使用家用 SSD 构建的 CEPH 来说,无疑是一场灾难,磁盘不用多久就会写报废,为了解决此问题,我们需要通过磁盘 IO 的占用,来反推是哪个服务占用磁盘 IO 高,再从服务入手从根本解决问题。通过查看 PVE 虚拟机磁盘读写 IO,确认磁盘 IO 占用大的为 Kubernetes 节点,所以从 Kubernetes 节点入手。

问题分析
问题处理的两个方向:
- 通过 Grafana 或 Prometheus PromQL 查看各命名空间的磁盘占用量,前提条件: 需要已经部署 Grafana 与 Prometheus,并且监控对应 Pod 的磁盘读写。
- 通过 Linux 命令行排查,确认 Pod 信息。
这是基于后者进行排查,并通过前者进行验证是否正确,主要提供基于 Linux 命令行的 Kubernetes 服务异常排查方法与思路。
大概步骤如下:
通过 iotop 命令获取读写磁盘比较大的 TID,通过 TID 获取 PID,通过 PID 获取容器 ID(Pod UID),通过容器 ID(Pod UID) 获取 Pod 信息。
详细步骤
获取磁盘 IO 占用高的 TID 信息
通过 iotop 命令,我们可以看到对应磁盘读写比较大的 TID 为: 3746531、3746532、1847465、1847466 。
[root@w01 ~]# iotop
Total DISK READ : 0.00 B/s | Total DISK WRITE : 9.08 M/s
Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 7.86 M/s
TID PRIO USER DISK READ DISK WRITE> COMMAND
3746531 be/4 root 0.00 B/s 1315.23 K/s java -Xmx2048m -jar /bitools.jar [http-nio-2231-e]
3746532 be/4 root 0.00 B/s 1315.23 K/s java -Xmx2048m -jar /bitools.jar [http-nio-2231-e]
1847465 be/4 root 0.00 B/s 1199.28 K/s java -Xmx2048m -jar /bitools.jar [http-nio-2232-e]
1847466 be/4 root 0.00 B/s 1199.28 K/s java -Xmx2048m -jar /bitools.jar [http-nio-2232-e]通过 TID 获取 PID、容器 ID、Pod UID
这里以 TID 3746531 为例,获取对应 PID 为 3746531,通过 cgroup 信息查看对应容器 ID,容器 ID 为: 5deb688d8c8482b2e600fa1f015368da01557883d97b7412817b8130c9049021,Pod UID 为: aabb49d1_9e29_4b30_ae7e_0225e02d8788。
[root@w01 ~]# cat /proc/3746531/status | grep "^Pid:"
Pid: 3746531
[root@w01 ~]# cat /proc/3746531/cgroup
0::/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-podaabb49d1_9e29_4b30_ae7e_0225e02d8788.slice/cri-containerd-5deb688d8c8482b2e600fa1f015368da01557883d97b7412817b8130c9049021.scope通过容器 ID 获取 Kubernetes Pod 信息
# 安装 jq
[root@w01 ~]# dnf install jq -y
# 获取 Pod 名称
[root@w01 ~]# crictl inspect 5deb688d8c8482b2e600fa1f015368da01557883d97b7412817b8130c9049021 | jq '.info.config.metadata'
{
"name": "bitools", # Pod 名称
"attempt": 82
}
# 当然可以通过 more 查看更多详细信息
[root@w01 ~]# crictl inspect 5deb688d8c8482b2e600fa1f015368da01557883d97b7412817b8130c9049021 | more
{
"status": {
"id": "5deb688d8c8482b2e600fa1f015368da01557883d97b7412817b8130c9049021",
"metadata": {
"attempt": 82,
"name": "bitools"
},
......(略)
"labels": {
"io.kubernetes.container.name": "bitools", # 容器名称
"io.kubernetes.pod.name": "bitools-7598784558-bsv2q", # Pod 名称
"io.kubernetes.pod.namespace": "test-bi", # 命令空间
"io.kubernetes.pod.uid": "aabb49d1-9e29-4b30-ae7e-0225e02d8788" # Pod UID
}有了 Pod 名称、命令空间,再进行排查就比较简单了 kubectl get pod <pod-name> -n <namespace>。
通过 Pod UID 获取 Kubernetes Pod 信息
这种方法的缺点是,当 Pod 数量过多时,遍历所有 Pod 会造成 Kubernetes 负载过高。另外通过 cgroup 查看到的 Pod UID 是下划线: aabb49d1_9e29_4b30_ae7e_0225e02d8788,而实际 Pod UID 是中横线: aabb49d1-9e29-4b30-ae7e-0225e02d8788,所以过滤的时候需要注意。
[root@m01 ~]# kubectl get pods --all-namespaces -o custom-columns='NAME:.metadata.name,UID:.metadata.uid,NAMESPACE:.metadata.namespace' | grep 0225e02d8788
bitools-7598784558-bsv2q aabb49d1-9e29-4b30-ae7e-0225e02d8788 test-bi最后,我们通过 Grafana Pod Dashboard 验证,不难看出对应 Pod 信息与我们命令行排查到的是一致的。
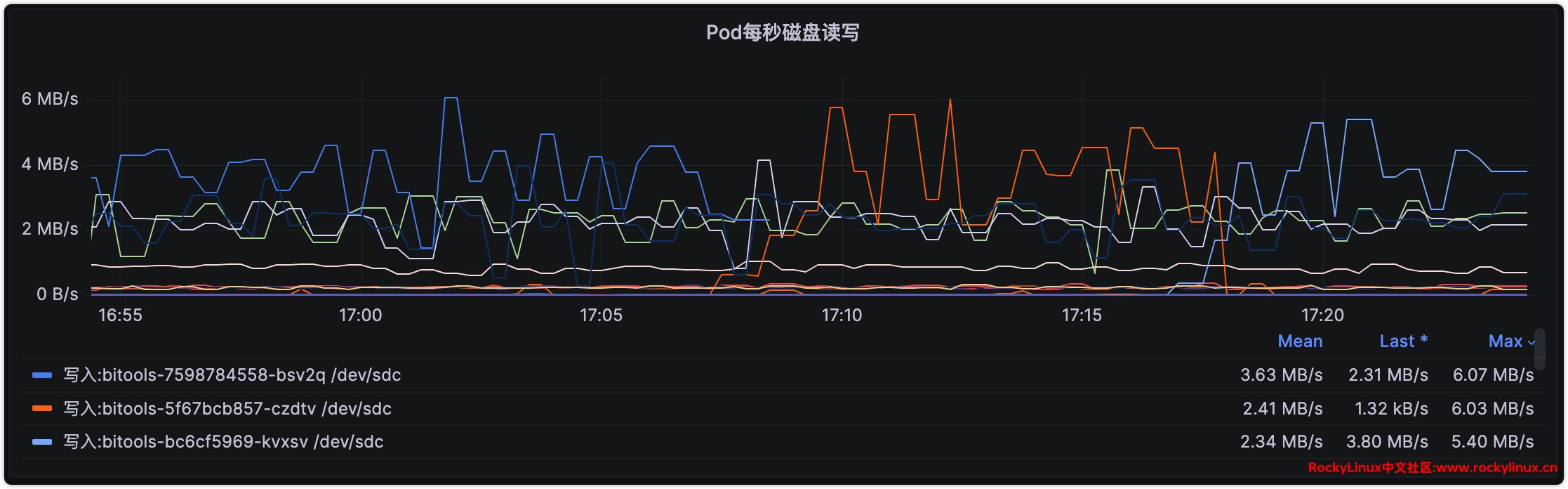
当然,我们也可以直接通过 PromQL 语句进行查询:
topk(10, irate(container_fs_writes_bytes_total{Kubernetes-cluster=~"Kubernetes"}[1m])) 程序分析
基于获取到的 Pod 信息,进入相关容器并使用 strace 对进程进行追踪后,观察到多个不同的进程频繁在 /tmp/ 目录进行创建和删除临时文件以及对 /down.jar 文件执行 stat(查询文件属性)、open(打开文件)、和 unlink(删除文件)等操作。这些操作是频繁的磁盘 I/O 写入活动的主要来源。
bash-5.1# ps -ef
PID USER TIME COMMAND
7 root 12:01 java -Xmx2048m -jar /down.jar
/down # strace -p 7
[pid 113] lstat("/tmp/jar_cache6840240073609488837.tmp", {st_mode=S_IFREG|0600, st_size=0, ...}) = 0
[pid 113] unlink("/tmp/jar_cache6840240073609488837.tmp") = 0
[pid 113] open("/tmp/jar_cache6840240073609488837.tmp", O_WRONLY|O_CREAT|O_EXCL|O_LARGEFILE, 0666) = 1003
[pid 114] stat("/tmp/jar_cache3881005007254439629.tmp", {st_mode=S_IFREG|0644, st_size=4738756, ...}) = 0
[pid 114] open("/tmp/jar_cache3881005007254439629.tmp", O_RDONLY|O_LARGEFILE|O_CLOEXEC) = 1004
[pid 114] unlink("/tmp/jar_cache3881005007254439629.tmp") = 0
[pid 114] open("/down.jar", O_RDONLY|O_LARGEFILE) = 1005
[pid 114] open("/tmp/jar_cache4526217245484136930.tmp", O_WRONLY|O_CREAT|O_EXCL|O_LARGEFILE, 0600) = 1005
[pid 114] lstat("/tmp/jar_cache4526217245484136930.tmp", {st_mode=S_IFREG|0600, st_size=0, ...}) = 0
[pid 114] unlink("/tmp/jar_cache4526217245484136930.tmp") = 0
[pid 114] open("/tmp/jar_cache4526217245484136930.tmp", O_WRONLY|O_CREAT|O_EXCL|O_LARGEFILE, 0666) = 1005
[pid 113] stat("/tmp/jar_cache6840240073609488837.tmp", {st_mode=S_IFREG|0644, st_size=4738756, ...}) = 0
[pid 113] open("/tmp/jar_cache6840240073609488837.tmp", O_RDONLY|O_LARGEFILE|O_CLOEXEC) = 1003
[pid 113] unlink("/tmp/jar_cache6840240073609488837.tmp") = 0
[pid 113] open("/down.jar", O_RDONLY|O_LARGEFILE) = 1006
[pid 113] open("/tmp/jar_cache876144302891423828.tmp", O_WRONLY|O_CREAT|O_EXCL|O_LARGEFILE, 0600) = 1006
[pid 113] lstat("/tmp/jar_cache876144302891423828.tmp", {st_mode=S_IFREG|0600, st_size=0, ...}) = 0
[pid 113] unlink("/tmp/jar_cache876144302891423828.tmp") = 0
[pid 113] open("/tmp/jar_cache876144302891423828.tmp", O_WRONLY|O_CREAT|O_EXCL|O_LARGEFILE, 0666) = 1006
[pid 114] stat("/tmp/jar_cache4526217245484136930.tmp", {st_mode=S_IFREG|0644, st_size=4738756, ...}) = 0
[pid 114] open("/tmp/jar_cache4526217245484136930.tmp", O_RDONLY|O_LARGEFILE|O_CLOEXEC) = 1005
[pid 114] unlink("/tmp/jar_cache4526217245484136930.tmp") = 0
[pid 113] stat("/tmp/jar_cache876144302891423828.tmp", {st_mode=S_IFREG|0644, st_size=4738756, ...}) = 0
[pid 113] open("/tmp/jar_cache876144302891423828.tmp", O_RDONLY|O_LARGEFILE|O_CLOEXEC) = 1006
[pid 113] unlink("/tmp/jar_cache876144302891423828.tmp") = 0
[pid 74] stat("/down.jar", {st_mode=S_IFREG|0644, st_size=96759246, ...}) = 0
[pid 74] stat("/down.jar", {st_mode=S_IFREG|0644, st_size=96759246, ...}) = 0
[pid 70] stat("/down.jar", {st_mode=S_IFREG|0644, st_size=96759246, ...}) = 0
[pid 70] stat("/down.jar", {st_mode=S_IFREG|0644, st_size=96759246, ...}) = 0
[pid 73] stat("/down.jar", {st_mode=S_IFREG|0644, st_size=96759246, ...}) = 0
[pid 73] stat("/down.jar", {st_mode=S_IFREG|0644, st_size=96759246, ...}) = 0
[pid 66] open("/down.jar", O_RDONLY|O_LARGEFILE) = 346
strace: Process 7 detached
strace: Process 8 detached
strace: Process 9 detached
strace: Process 10 detached
strace: Process 11 detached
strace: Process 12 detached
strace: Process 13 detached
strace: Process 14 detached
strace: Process 15 detached
strace: Process 16 detached
strace: Process 17 detached
strace: Process 18 detached
strace: Process 19 detached
strace: Process 20 detached
strace: Process 21 detached
strace: Process 22 detached
strace: Process 23 detached
strace: Process 24 detached使用 pidstat 观察到特定的线程 http-nio-2231-e 在某些时刻会突然执行大量的磁盘写操作。为了进一步分析这个问题,我们运用了 jstack 工具来检查该线程的行为。jstack 的输出显示,http-nio-2231-e 线程主要在执行与 swagger 相关的操作。根据这一发现,我们可以初步判断,问题很可能是由于 Java 线程频繁调用 swagger 相关功能所引起的。
具体来说,这个线程似乎每次都会从 springfox-swagger-ui-2.8.0.jar 文件中提取 swagger-ui.html 页面和相关资源,以便进行输出。这个过程涉及到将 springfox-swagger-ui-2.8.0.jar 文件拷贝到磁盘并解压,请求处理完成后,又会删除这些临时文件。由于这个 jar 包的大小约为 4MB,这与我们监测到的 Pod 磁盘写入数据非常接近,因此可以较为确信,这些磁盘操作就是由于 swagger 页面资源的提取和清理过程所导致的。
# 安装 pidstat 工具
apk add sysstat
# 使用 pidstat 进行进程分析,发现 http-nio-2232-e 线程会突然执行大量的磁盘写操作。
/down # pidstat -d -t 7
Linux 6.1.1-1.el9.elrepo.x86_64 (bitools-7598784558-bsv2q) 10/22/23 _x86_64_ (40 CPU)
18:37:43 UID TGID TID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
18:37:50 0 7 - 0.00 1204.56 0.00 0 java
18:37:50 0 - 48 0.00 0.57 0.00 0 |__C2 CompilerThre
18:37:50 0 - 57 0.00 1.14 0.00 0 |__VM Periodic Tas
18:37:50 0 - 73 0.00 0.57 0.00 0 |__pool-5-thread-7
18:37:50 0 - 87 0.00 1202.28 0.00 0 |__http-nio-2231-e
18:37:50 UID TGID TID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
18:37:57 0 7 - 0.00 1208.00 0.00 0 java
18:37:57 0 - 37 0.00 1.14 0.00 0 |__VM Thread
18:37:57 0 - 57 0.00 1.14 0.00 0 |__VM Periodic Tas
18:37:57 0 - 88 0.00 1205.71 0.00 0 |__http-nio-2231-e
18:37:57 UID TGID TID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
18:38:04 0 7 - 0.00 3620.00 0.00 0 java
18:38:04 0 - 41 0.00 1.14 0.00 0 |__C2 CompilerThre
18:38:04 0 - 57 0.00 1.14 0.00 0 |__VM Periodic Tas
18:38:04 0 - 73 0.00 0.57 0.00 0 |__pool-5-thread-7
18:38:04 0 - 79 0.00 1205.71 0.00 0 |__http-nio-2231-e
18:38:04 0 - 80 0.00 1205.71 0.00 0 |__http-nio-2232-e
18:38:04 0 - 82 0.00 1205.71 0.00 0 |__http-nio-2233-e
18:38:04 UID TGID TID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
18:38:11 0 7 - 0.00 1208.57 0.00 0 java
18:38:11 0 - 51 0.00 1.14 0.00 0 |__C1 CompilerThre
18:38:11 0 - 57 0.00 1.14 0.00 0 |__VM Periodic Tas
18:38:11 0 - 75 0.00 0.57 0.00 0 |__Thread-6
18:38:11 0 - 81 0.00 1205.71 0.00 0 |__http-nio-2231-e
# 再通过 jstack 分析对应进程,发现线程 http-nio-2231-e 仅仅持续在操作 swagger
/down # jstack 7
"http-nio-2231-e" #51 daemon prio=s os_prio=0 tid=0x00007efd35ab8800 nid=0x56 runnable [0x00007efd2ed01000]
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193)
at org.apache.catalina. core.ApplicationFilterChain.doFilter (ApplicationFilterChain.java: 166)
at com.apache.ppg.commong.confid.swagger.Swagger2Configuration$1.doFilter (Swagger2Configuration.java: 81)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter (ApplicationFilterChain.java: 193)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166)
at org.springframework.web.filter.RequestContextFilter.doFilterInternal (RequestContextFilter.java: 99)解决方法
知道问题原因,处理起来相对就比较简单了,目前有两个方案:
1、将 springfox-swagger-ui-2.8.0.jar 解压至 /tmp 目录,永久缓存。
2、将 Kubernetes 使用 swagger-ui.html 页面进行健康检测更换成其它页面。
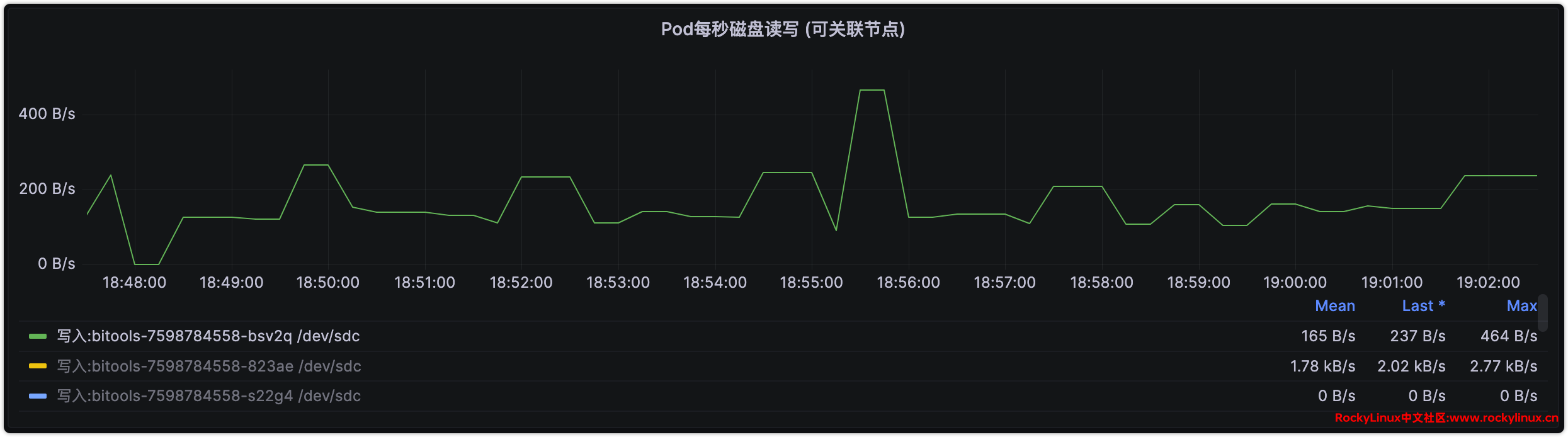
这里选择后者,更换 Kubernetes 健康检测路径后,Pod 流量瞬间下降,CEPH 流量也从 50+MiB/s 下降至 10+MiB/s,详见如下图,至此问题完美解决,再也不用担心家用 SSD 写爆了。

变更记录
- 2024-03-01
- 新增程序分析与解决方法。










