
最近有同事反馈 Kubernetes 节点会无故重启。经过同事分析后,认为这可能是由于 Linux 内核的一个 Bug 引起的。起初,木子认为这种级别的 Bug 不太可能轻易遇到,但在认真分析问题后,发现确实如此。以下记录了整个问题排查和分析的过程,希望能对后续遇到类似问题的人有所帮助。当然,这个过程中对 Issue 的跟踪也可能为大家提供一些思路上的启发。
错误信息
所有 Linux 内核为 6.1.1-1.el9.elrepo.x86_64 的,都会在 1-2 天内出现系统重启,但内核 6.1.81-1.el9.elrepo.x86_64 从未发生过重启。从这里来看通过升级内核即可解决,但木子还想试着分析一下具体原因。
[root@m01 ~]# kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
m01 Ready control-plane 650d v1.26.0 192.168.1.111 <none> Rocky Linux 9.1 (Blue Onyx) 6.1.1-1.el9.elrepo.x86_64 containerd://1.6.28
m02 Ready control-plane 650d v1.26.0 192.168.1.112 <none> Rocky Linux 9.1 (Blue Onyx) 6.1.1-1.el9.elrepo.x86_64 containerd://1.6.28
m03 Ready control-plane 650d v1.26.0 192.168.1.113 <none> Rocky Linux 9.1 (Blue Onyx) 6.1.1-1.el9.elrepo.x86_64 containerd://1.6.28
w01 Ready worker 650d v1.26.0 192.168.1.121 <none> Rocky Linux 9.1 (Blue Onyx) 6.1.1-1.el9.elrepo.x86_64 containerd://1.6.28
w02 Ready worker 650d v1.26.0 192.168.1.122 <none> Rocky Linux 9.1 (Blue Onyx) 6.1.1-1.el9.elrepo.x86_64 containerd://1.6.28
w03 Ready worker 650d v1.26.0 192.168.1.123 <none> Rocky Linux 9.1 (Blue Onyx) 6.1.1-1.el9.elrepo.x86_64 containerd://1.6.28
w04 Ready worker 650d v1.26.0 192.168.1.124 <none> Rocky Linux 9.1 (Blue Onyx) 6.1.1-1.el9.elrepo.x86_64 containerd://1.6.28
w05 Ready worker 650d v1.26.0 192.168.1.125 <none> Rocky Linux 9.1 (Blue Onyx) 6.1.1-1.el9.elrepo.x86_64 containerd://1.6.28
w06 Ready worker 650d v1.26.0 192.168.1.126 <none> Rocky Linux 9.1 (Blue Onyx) 6.1.1-1.el9.elrepo.x86_64 containerd://1.6.28
w07 Ready worker 200d v1.26.0 192.168.1.127 <none> Rocky Linux 9.1 (Blue Onyx) 6.1.81-1.el9.elrepo.x86_64 containerd://1.6.28错误信息如下,当触发 Kernel BUG 后,Rocky Linux 9.1 内核 6.1.1-1.el9.elrepo.x86_64 服务器将会自动重启。
[root@w01 ~]# grep -R "kernel BUG" /var/log/messages*
/var/log/messages-20240618:Aug 16 00:15:16 w01 kernel: kernel BUG at net/core/skbuff.c:4230!
/var/log/messages-20240701:Aug 29 09:52:37 w01 kernel: kernel BUG at net/core/skbuff.c:4230!
/var/log/messages-20240822:Aug 31 20:50:26 w01 kernel: kernel BUG at net/core/skbuff.c:4230!
[root@w01 ~]# uname -r
6.1.1-1.el9.elrepo.x86_64
# 详细错误日志
[root@w01 ~]# grep -A 10 -R "kernel BUG" /var/log/messages*
/var/log/messages-20240618-Aug 13 15:59:23 w01 kernel: ------------[ cut here ]------------
/var/log/messages-20240618:Aug 13 15:59:23 w01 kernel: kernel BUG at net/core/skbuff.c:4230!
/var/log/messages-20240618-Aug 13 16:00:30 w01 kernel: Linux version 6.1.1-1.el9.elrepo.x86_64 (mockbuild@10b614fb6a184fe480a3a09c0bdfdd47) (gcc (GCC) 11.3.1 20220421 (Red Hat 11.3.1-2), GNU ld version 2.35.2-24.el9) #1 SMP PREEMPT_DYNAMIC Tue Dec 20 09:27:32 EST 2022
/var/log/messages-20240618-Aug 13 16:00:30 w01 kernel: Command line: BOOT_IMAGE=(hd0,msdos1)/vmlinuz-6.1.1-1.el9.elrepo.x86_64 root=/dev/mapper/rl-root ro crashkernel=1G-4G:192M,4G-64G:256M,64G-:512M resume=/dev/mapper/rl-swap rd.lvm.lv=rl/root rd.lvm.lv=rl/swap ipv6.disable=1 selinux=0 user_namespace.enable=1
/var/log/messages-20240618-Aug 13 16:00:30 w01 kernel: x86/fpu: Supporting XSAVE feature 0x001: 'x87 floating point registers'原因分析
明确标识错误发生在内核文件 net/core/skbuff.c 的 4230 行,错误行内容:BUG_ON(skb_headlen(list_skb) > len); 。
# 拉取对应分支代码
git clone --branch v6.1.1 --depth 1 https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git
# 进入 linux 目录,查看 skbuff.c 文件 4230 行
cd linux
vi net/core/skbuff.c
do {
struct sk_buff *nskb;
skb_frag_t *nskb_frag;
int hsize;
int size;
if (unlikely(mss == GSO_BY_FRAGS)) {
len = list_skb->len;
} else {
len = head_skb->len - offset;
if (len > mss)
len = mss;
}
hsize = skb_headlen(head_skb) - offset;
if (hsize <= 0 && i >= nfrags && skb_headlen(list_skb) &&
(skb_headlen(list_skb) == len || sg)) {
BUG_ON(skb_headlen(list_skb) > len);# 此行为 4230 行
i = 0;
nfrags = skb_shinfo(list_skb)->nr_frags;从源码来看,当 skb_headlen(list_skb) 返回值大于 len 时,就会触发 BUG_ON 内核崩溃 (kernel panic)。
当然我们也可以通过 linux/net/core/skbuff.c at v6.1 · torvalds/linux · GitHub 查看对应 Linux 内核代码。

从错误来看明显与网络有关 net/core,而木子使用的是 Calico + BGP 模式,于是 Google Calico BUG_ON(skb_headlen(list_skb) > len); 这行代码,找到 kernel BUG at net/core/skbuff.c:4044! · Issue #8771,引文中提到解决方法以及另外一个 Issue #6865。
Disabled GRO and GSO is active.
ethtool –offload eth0 gro off
ethtool –offload eth0 gso off
The patch mentioned in this #6865 doesn’t work for me.
analysis the vmcore, it was crashed at BUG_ON(skb_headlen(list_skb) > len).
The gso_size is 75, the frag_list has one element which head_frag is 1. the skb_shared_info struct is as following.
这个 Issue #6865,提供了对应的解决方案,和上面引文中的一致。
ethtool --offload eth0 gro off
ethtool --offload eth0 gso off查看 Kubernetes 节点,当前为启用状态。
[root@w01 ~]# ethtool -k ens18 | grep -E 'generic-receive-offload|generic-segmentation-offload'
generic-segmentation-offload: on
generic-receive-offload: on这个 Issue #6865,其中一段描述提到,不仅仅是禁用 GRO,还需要禁用 GSO,并关联了一个另一个 Issue:flatcar/Flatcar#378 (comment)
Thank you filing this issue. I noticed that to work around this problem, you disabled GRO, but not GSO. @igcherkaev had recommended disabling both in flatcar/Flatcar#378 (comment), and we had found that disabling just one of the two insufficient, but that was with an older kernel version than we’ve been using over the last couple of weeks. Perhaps we should try enabling GSO again.
在这个 Issue flatcar/Flatcar#378 (comment) 中提到,已经在 v6.1-rc5 内核版本中修复了此问题,但仅仅是类似错误,并非同一问题。
I see that the patch is present along Linux’s "master" branch and is tagged with "v6.1-rc5" as of three days ago.
点击对应链接 linux/net/core/skbuff.c at v6.1-rc5 · torvalds/linux · GitHub,可以看到对应变更记录。
详细修复关联 [commit] 信息如下:
Since commit 3dcbdb1 ("net: gso: Fix skb_segment splat when
splitting gso_size mangled skb having linear-headed frag_list"), it is
allowed to change gso_size of a GRO packet. However, that commit assumes
that "checking the first list_skb member suffices; i.e if either of the
list_skb members have non head_frag head, then the first one has too".
It turns out this assumption does not hold. We’ve seen BUG_ON being hit
in skb_segment when skbs on the frag_list had differing head_frag with
the vmxnet3 driver. This happens because netdev_alloc_skb and
napi_alloc_skb can return a skb that is page backed or kmalloced
depending on the requested size. As the result, the last small skb in
the GRO packet can be kmalloced.

到这里只知道它在 v6.1-rc5 中已经提交了,这时候可以在 Linux 内核稳定版本和后续的修补版本仓库 kernel/git/stable/linux.git – Linux kernel stable tree 中搜索对应提交信息:fix panic on frag_list with mixed head alloc types,可以看到作者 Jiri Benc 在 2022-11-03 提交,并由 Linus Torvalds 于 2022-11-10 合并 Tag net-6.1-rc5 。

commit ID 为:9e4b7a99a03aefd37ba7bb1f022c8efab5019165 。
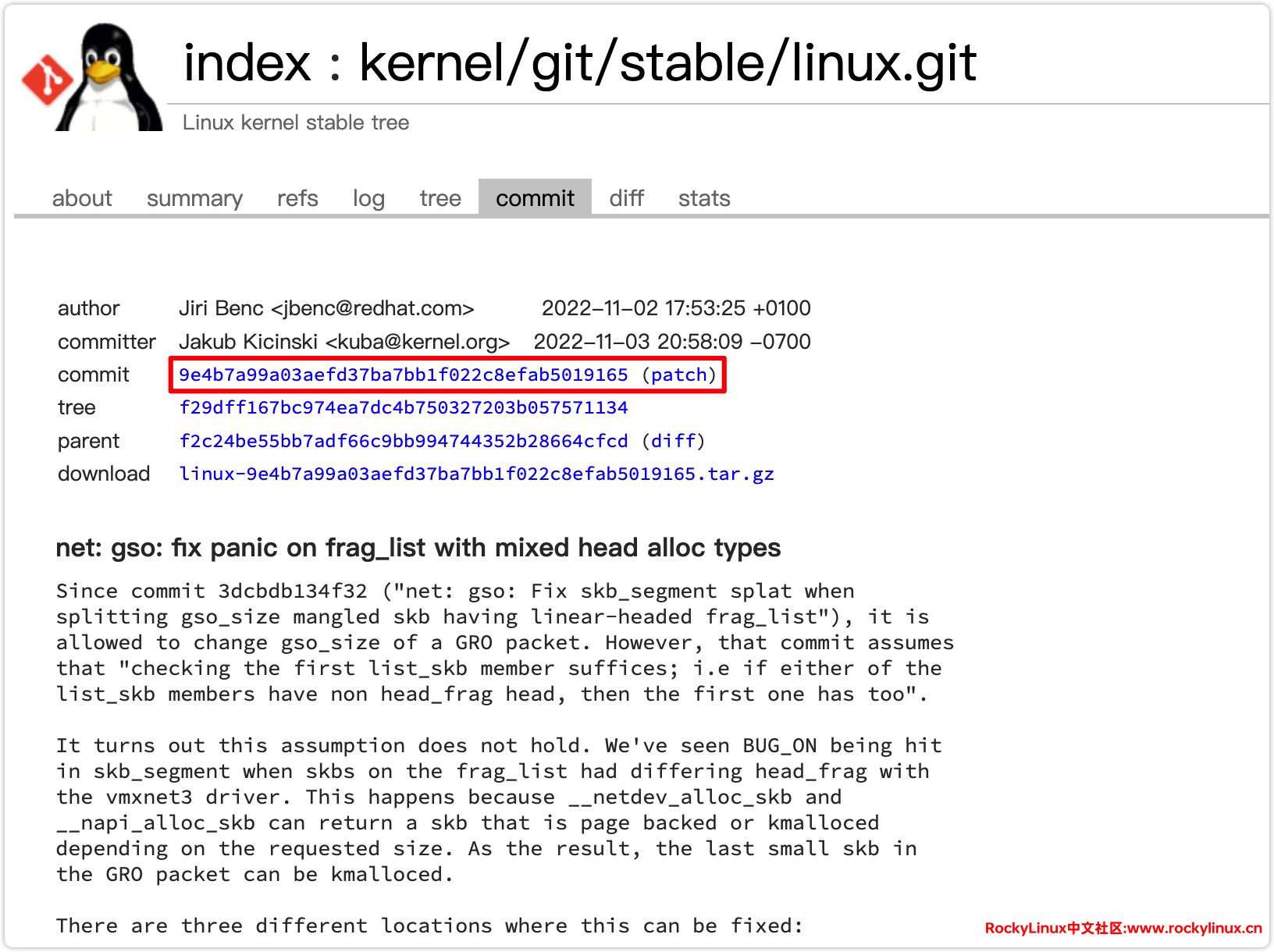
拉取稳定版 Linux 仓库,查看对应 commit ID,可以看到 v6.1-rc5 确实已经修复此 Bug。
❯ git clone https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git
❯ git tag --contains 9e4b7a99a03aefd37ba7bb1f022c8efab5019165
v6.1
v6.1-rc5
v6.1-rc6
v6.1-rc7
v6.1-rc8
v6.1.1
v6.1.10
v6.1.100为什么木子内核版本是 v6.1.1,还会出现这个问题了?显然不是同一个问题🙈🤦,此错误仅仅只是类似,并非同一问题。
从这个 Issue kernel BUG at net/core/skbuff.c:4044! · Issue #8771 · projectcalico/calico · GitHub 来看,用户 dracoding 在 kernel 6.6.35 内核也出现此 Bug,并且已经向社区提交了补丁。
I have tested on kernel 6.6.35, it also has the problem and I have submitted a patch to the community.
https://lore.kernel.org/all/[email protected]/
而在稳定版 Linux 仓库中,木子搜索相关 skbuff.c commit 也很多,显然相应的 Bug 存在很多。
解决方法
如前面所述,有两种解决方法:
- 禁用 GRO 和 GSO。(木子未进行测试验证)
- 升级 Linux 内核。(木子升级到了最新的
v6.1.109内核)– 参考文献:Rocky Linux 9.x 内核升级至 6.x – Rocky Linux
其实在整个过程中,木子还尝试 debug 内核错误信息,但未发现更多有价值的线索,故未继续跟踪(排查过程略)。
结论
Linux 内核崩溃(kernel panic)的原因多种多样,涵盖了很多软硬件问题。在特定条件下,可能会触发不同的 Bug。例如:在 PVE 搭配 Calico BGP 和 Cisco 交换机,或 AWS 上的 EKS,以及 AKS 配合 Flannel 的场景下,不同的软件组合、硬件配置和云平台都可能导致不同的 Bug。针对这些多样化的问题,我们需要仔细分析并根据可能的原因进行排查。虽然结果可能不尽如人意,但在排查和分析问题的过程中,我们会收获很多。
自系统内核升级到 v6.1.109 后,截至本文发稿时,系统已经稳定运行了半年,未再发生任何重启现象。如果后期仍出现重启问题,木子将持续更新本文,记录相关的排查和解决过程。










