
简述
Keepalived: 是一个用 C 语言编写的路由软件,该软件项目的主要目标是为 GNU/Linux 系统和基于 GNU/Linux 的基础设施提供简单而强大的 负载均衡 以及 高可用。负载均衡框架依赖著名和广泛使用的 IPVS 内核模块,提供 第四层的负载均衡。
keepalived 实现了一套检查器,可根据服务器状态动态地、自适应地维护以及管理服务器池,以达到负载均衡。另外,其 HA(高可用)是使用 VRRP 协议实现的。为了实现最快的网络故障检测,keepalived 还实现了 BFD 协议。截至本文发布前,keepalived 最新版本为 2.3.2(2024年12月21日)。
您可以该链接访问其他更多的信息 —— https://keepalived.org/
github 存储库 —— https://github.com/acassen/keepalived
术语解释
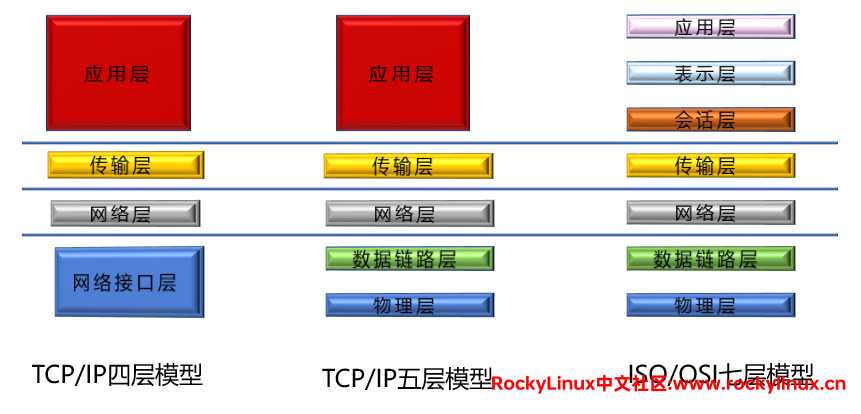
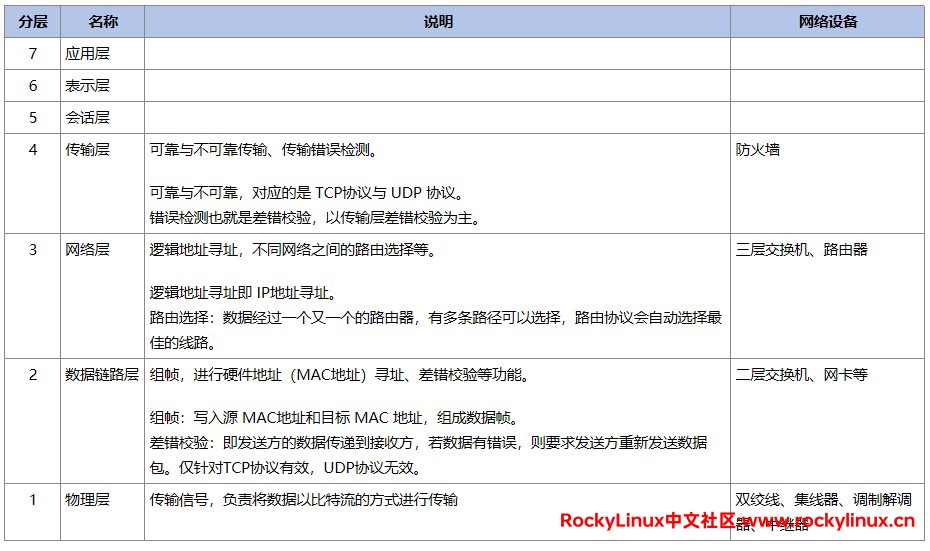
第四层的负载均衡(四层负载均衡):我们常说的 ISO/OSI 七层模式是指 物理层、数据链路层、网络层、传输层、会话层、表示层、应用层。ISO/OSI 只是一个理论的参考模型,现实中并不存在,一般使用的是 TCP/IP 五层模型。工作在第四层,即能够对 "IP地址 + 端口" 进行负载均衡。
IPVS(IP Virtual Server,IP虚拟服务器):是一种通过 Linux 内核实现的负载均衡技术,LVS 也是利用该技术实现的负载均衡能力,更多介绍请参阅这里 —— http://www.linuxvirtualserver.org/index.html
VRRP(Virtual Router Redundancy Protocol,虚拟路由器冗余协议):从名称就可以知道,该协议可以避免由于 LAN 网网关的单点故障而导致的网络中断,它能够在不改变组网的情况下,将多个网关加入一个组中,虚拟成一个虚拟网关,有了虚拟网关,也就有了 虚拟IP地址(VIP)。
- 协议版本有 VRRPv2 和 VRRPv3
- VRRPv2 适用于 IPv4 网络;VRRPv3 适用于 IPv4 和 IPv6 两种网络
- Advertisemen 报文,目的IP地址 224.0.0.18,目的 MAC地址 01-00-5e-00-00-12
网关:也叫默认路由, 是一台拥有路由功能的网络设备,可以是路由器,也可以是一台电脑,但前提必须拥有一定的功能,其最主要的是 NAT转发 以及分隔广播域功能。可简单理解为只要 LAN 网处理不了的数据包,都交给网关来处理。通常所说的的网关指的是工作在第三层的路由器。
工作原理
最简单的网络拓扑中,它是这样的:
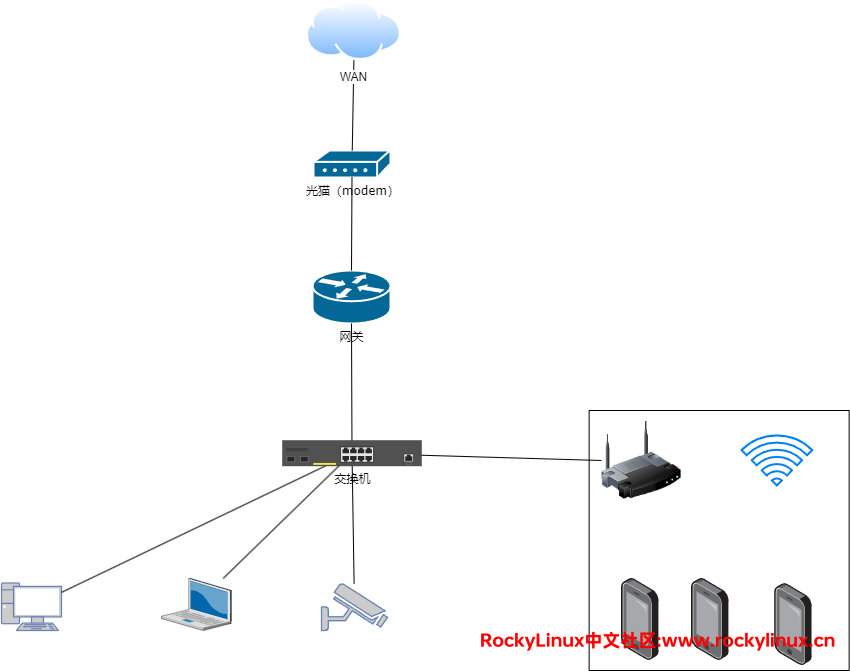
正常情况下,若终端想要访问 WAN 的资源,则路由器(网关)会根据路由表将数据包进行三层的转发。当路由器(网关)出现任意的故障时,则 LAN 网的所有终端设备无法访问 WAN 网,我们将这种故障称为 网关单点故障。
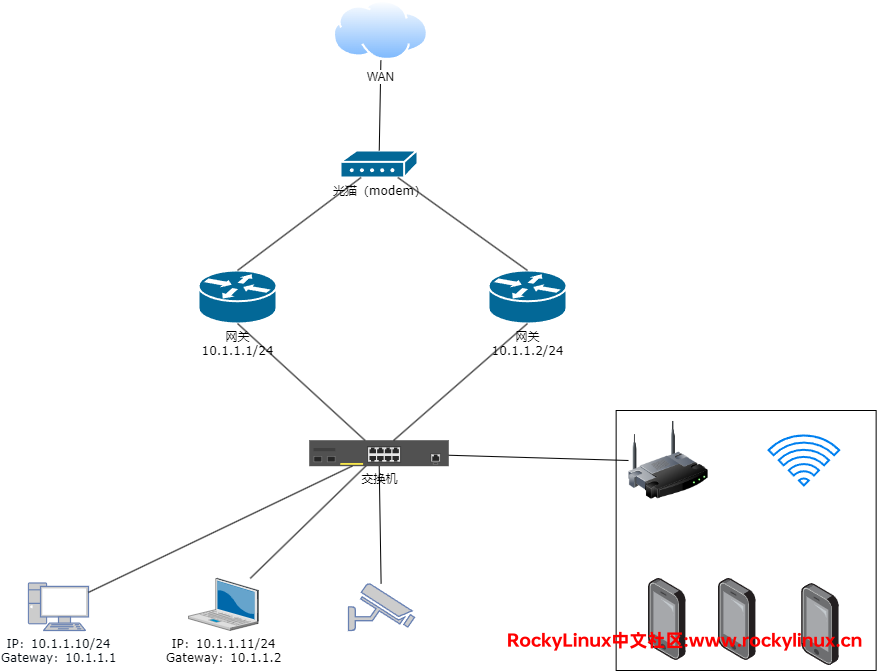
我们知道,任意的终端设备(手机、电脑、平板等),它的网关都只能配置一个,不管你是通过手工静态配置还是通过 DHCP 。为了避免网关的单点故障,此时可通过部署多个网关来解决,那么如何让多个网关协同工作且不会互相冲突呢?答案是 VRRP。比如说,有两台网关设备,它们 LAN网 物理网卡的 IP地址 是肯定不能相同的。但这也带来一个问题,就是如果某一个终端填写的网关是故障网关的其中一个,那就需要人工干预,达不到冗余的效果(不能自动的切换网关)。
Q:VRRP 是如何工作的?
当有一组两台网关设备时,若使用了 VRRP 这个协议,这两台网关设备的相应端口会协商出一个 主(Master) 和 备(Backup),当然你可以通过调整 priority 的值指定谁是 主 谁是 备,值范围为 0-255(手工能配置的值为 1-254),值数字越大,优先级越高 。终端设备的网关就是那个 虚拟IP地址(VIP)。
注:由几台网关组成的虚拟网关又称为 VRRP备份组
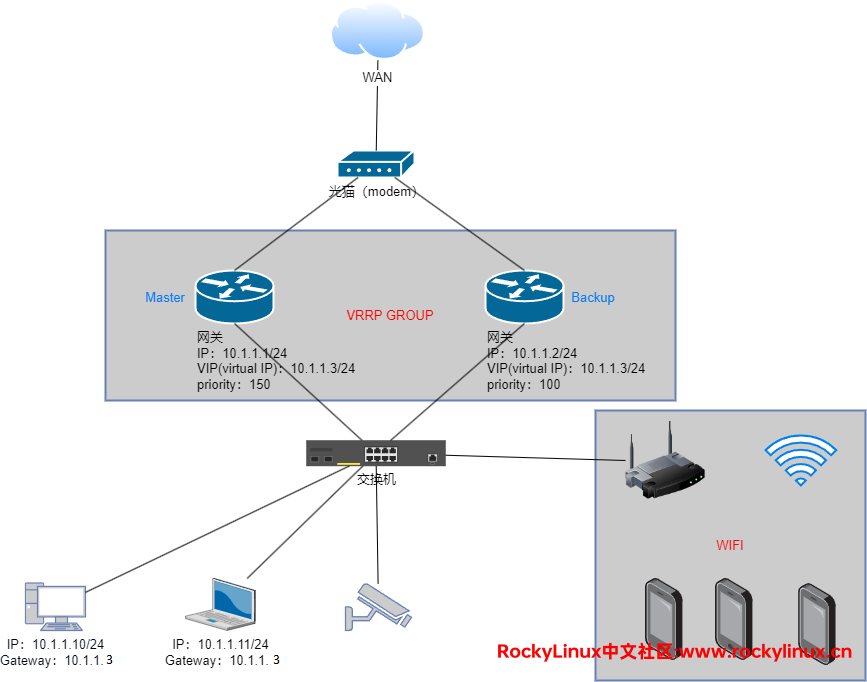
当两台网关都正常时,一旦两台网关设备完成了 VRRP 配置,则 Master 网关会一直向 Backup 网关周期性地发 Advertisement 报文, 以报告组的其他设备,自己处于正常状态,Backup 网关则会监听来自 Master 网关的报文。此时请求、转发、响应的过程是:终端 <——> 交换机 <——> Master网关 <——>光猫 <——> WAN
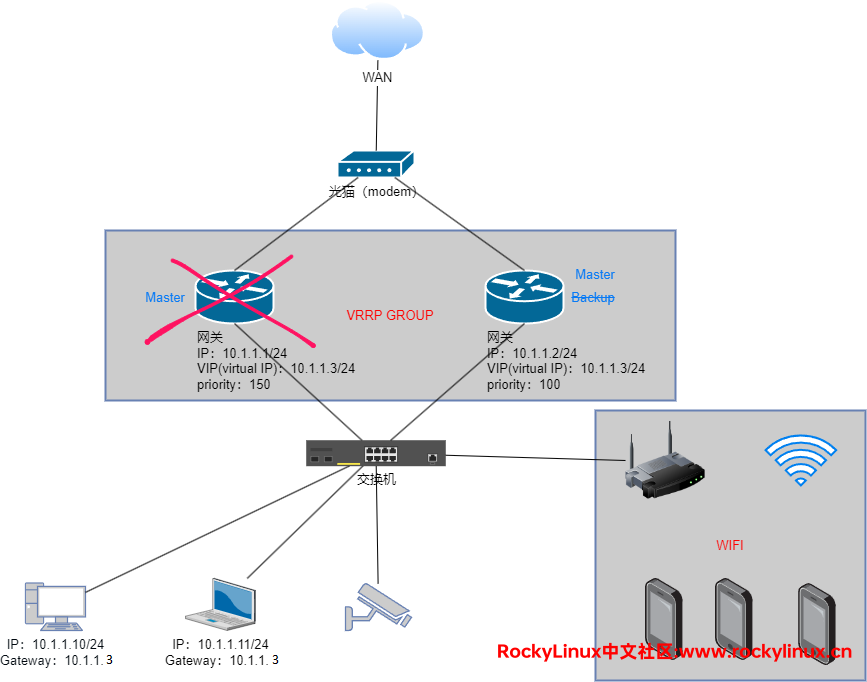
当 Master网关 发生了故障,若 Backup网关 在 Master_Down_Interval 时间内未收到来着 Master网关的 Advertisement 报文,会立即成为 Master网关,由于成为了 Master网关,则也会周期性的发送 Advertisement 报文。此时请求、转发、响应的过程是:终端 <——> 交换机 <——> Backup网关(Master) <——>光猫 <——> WAN
当 Master网关从故障中恢复过来,VRRP 里有个东西叫 抢占模式(preempt mode),若发现我的 priority 值比你的高,于是把 Master 抢过来,重新成为 Master网关。此时请求、转发、响应的过程是:终端 <——> 交换机 <——> Master网关 <——>光猫 <——> WAN
Q:是不是一定要 Master网关 故障才能发生主备切换?
并不是。若 Master网关 与 交换机 之间的链路故障了,也是可以切换的,因为 Backup网关 收不到它的报文。
Q:初始状态下,若两台网关的 priority 值一样,怎么协商出 Master 和 Backup?
根据物理网卡的IP地址大小,大的那个会成为 Master。
Q:VRRP 组里的网关成员数量一定要 2 台吗?
不是,是至少 2 台。
Q:主备切换再到旧 Master 恢复,priority 值高这个旧 Master 一定能够成为Master吗?
不一定,要看是抢占模式还是非抢占模式。
Q:VRRP 中的 VRID 是什么?
用来标识每一组 VIP,值范围为 1~255
Q:为什么需要 BFD?
BFD(Bidirectional Forwarding Detection,双向转发检测):一种基于 RDC 2880 标准的高速检测机制,两个系统建立了 BFD 会话后,在它们之间的通道上周期性地发送 BFD 报文,如果一方在协商的检测时间内没有接收到 BFD 报文,则认为这条双向通道上发生了故障。上层协议通过BFD感知到链路故障后可以及时采取措施,进行故障恢复。
在实际的企业与IDC中,网络中断会严重的影响业务正常运行并造成重大损失,为了提高可靠性,网络设备需要尽快检测与相邻设备间的通信故障,以便采取正确的措施保证业务正常运行。
有些同学可能会想到 SDH(Synchronous Digital Hierarchy,同步数字体系),它是通过硬件检测信号来检测链路故障,但并不是所有的介质都能提供硬件检测。此时,应用就要依靠上层协议自身的 Hello 报文机制来进行故障检测。上层协议的检测时间通常在秒级,当数据传输速率达到GB级时,秒级检测时间内,大量数据将会丢失。在三层网络中,Hello 报文检测机制无法针对所有路由来检测故障(如静态路由),这对系统间互联互通定位故障造成困难。
BFD 协议就是在这种背景下产生的,BFD 提供了一个通用的、标准化的、与介质和协议无关的快速故障检测机制,它具有以下优点:
- 提供轻负荷、短周期的故障检测,故障检测时间可达到毫秒级,可靠性更高。
- 支持多种故障检测,如接口故障、数据链路故障、转发引擎本身故障等。
- 不依赖专有硬件,能够对任何介质、任何协议层进行实时检测。
通常来说 ,BFD 不能独立运行,而是作为辅助与接口状态或路由协议(如静态路由、OSPF、IS-IS、BGP等)联动使用。










