
前言
在了解 Redis 的复制技术之前,我们先来看看 MySQL 的主从复制。
MySQL 的日志类型
服务层面的日志:
- 错误日志(Error log) – 记录 MySQL程序本身启动、停止、运行时所遇到的问题。默认开启,无法关闭。
- 常规查询日志(General query log) – 记录客户端连接后,执行了哪些 SQL 语句。默认关闭,即系统变量 general-log 的值为 OFF 。
- 二进制日志(Bin log) – 记录任何 成功执行 后引起 数据变化 的日志。select、show、事务的回滚、语法错误未能成功执行的,不会记录。默认开启,即系统变量 log_bin 的值为 ON 。
- 慢查询日志(Slow query log) – 用来记录在 MySQL 中响应时间超过阀值的语句。例如当你的 MySQL 性能下降时,可开启该日志进行分析处理。默认关闭,即系统变量 slow_query_log 的值为 OFF 。
- 中继日志(Relay log) – 主从同步架构中,记录与主服务器同步后收到的数据更改。
innodb 存储引擎的日志:
- 重做日志(redo log) – 属于事务方面的日志,保证事务 ACID 中的 D(持久性)
- 回滚日志(undo log) – 属于事务方面的日志,保证事务 ACID 中的A(原子性)
这几种日志类型当中,可以直接通过 vim 等打开的有:错误日志(error log)、常规查询日志(General Query Log)
只能通过 mysqbinlog 命令打开的有:二进制日志(bin log)、慢查询日志(slow query log)、中继日志(relay log)、重做日志(redo log)、回滚日志(undo log)
注:日志开启会占用 MySQL 的性能,所以在默认情况下,常规查询日志、慢查询日志是关闭的,这是合理的。
操作 binlog
众所周知,binlog 文件的作用主要有:
- 主从复制,在主从复制的模式中,主服务器(master)必须开启 binlog 来保证数据的一致性
- 基于时间点的恢复还原,因为 binlog 是以 事件(event)的形式记录到文件当中。事件,也称「事件调度器」,主要的作用是调用数据库对象且让其周期性运行,用来实现 MySQL 的计划任务,它是基于时间触发的定时任务。
- 更改数据的操作进行审计
每当 MySQL 服务器 重启/启动 时,binlog 就会自动生成带数字后缀的文件名,如 binlog.000001、binlog.000002 这样的。
binlog还有三种格式:
- ROW,默认格式,不记录具体的 SQL 语句,仅保存 SQL 语句执行成功后的每一行数据修改。该格式的特点是记录非常详细,占用的存储空间大,但是它能解决主从同步数据不一致的问题
- STATEMENT,以 SQL 语句的形式保存修改数据,SQL语句可以是 DDL、DML 等
- MIXED,前两者的混合
Q:binlog 真的可以恢复过往变更的数据吗?
先查看 binlog 的基本信息:
Mysql> show session variables like '%log_bin%';
+---------------------------------+------------------------------------+
| Variable_name | Value |
+---------------------------------+------------------------------------+
| log_bin | ON |
| log_bin_basename | /usr/local/mysql/data/binlog |
| log_bin_index | /usr/local/mysql/data/binlog.index |
| log_bin_trust_function_creators | OFF |
| log_bin_use_v1_row_events | OFF |
| sql_log_bin | ON |
+---------------------------------+------------------------------------+
6 rows in set (0.00 sec)
Mysql> show binary logs;
+---------------+-----------+-----------+
| Log_name | File_size | Encrypted |
+---------------+-----------+-----------+
| binlog.000001 | 501 | No |
| binlog.000002 | 180 | No |
| binlog.000003 | 1473321 | No |
| binlog.000004 | 948 | No |
| binlog.000005 | 1953 | No |
| binlog.000006 | 503 | No |
| binlog.000007 | 157 | No |
+---------------+-----------+-----------+ 创建库创建表并进行一些新增和删除数据的操作:
Mysql > create database world1;
Mysql > use world1;
Mysql > create table if not exists t1(
id int primary key auto_increment,
name varchar(10)
);
Mysql > insert into t1 values(null,'zhang'),(null,'li');
Mysql > insert into t1 values(null,'wang'),(null,'hong');
Mysql > delete from t1 where id between 1 and 4;刷下binlog,生成 binlog.000008
Mysql > flush logs;查看 binlog.000007 的起始,一个 BEGIN 开头到下一个 BEGIN 之前,就是一个事件。注意这里的 Pos 和 End_log_pos
Mysql > show binlog events in 'binlog.000007';
| Log_name | Pos | Event_type | Server_id | End_log_pos | Info
| binlog.000007 | 421 | Query | 1 | 535 | create database world1 /* xid=132 */ |
| binlog.000007 | 535 | Anonymous_Gtid | 1 | 614 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' |
| binlog.000007 | 614 | Query | 1 | 792 | use `world1`; create table if not exists t1(
id int primary key auto_increment,
name varchar(10)
) /* xid=137 */ |
| binlog.000007 | 792 | Anonymous_Gtid | 1 | 871 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' |
| binlog.000007 | 871 | Query | 1 | 948 | BEGIN |
| binlog.000007 | 948 | Table_map | 1 | 1006 | table_id: 97 (world1.t1) |
| binlog.000007 | 1006 | Write_rows | 1 | 1060 | table_id: 97 flags: STMT_END_F |
| binlog.000007 | 1060 | Xid | 1 | 1091 | COMMIT /* xid=138 */ |
| binlog.000007 | 1091 | Anonymous_Gtid | 1 | 1170 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' |
| binlog.000007 | 1170 | Query | 1 | 1247 | BEGIN |
| binlog.000007 | 1247 | Table_map | 1 | 1305 | table_id: 97 (world1.t1) |
| binlog.000007 | 1305 | Write_rows | 1 | 1360 | table_id: 97 flags: STMT_END_F |
| binlog.000007 | 1360 | Xid | 1 | 1391 | COMMIT /* xid=139 */ |
| binlog.000007 | 1391 | Anonymous_Gtid | 1 | 1470 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' |
| binlog.000007 | 1470 | Query | 1 | 1547 | BEGIN |
| binlog.000007 | 1547 | Table_map | 1 | 1605 | table_id: 97 (world1.t1) |
| binlog.000007 | 1605 | Delete_rows | 1 | 1668 | table_id: 97 flags: STMT_END_F |
| binlog.000007 | 1668 | Xid | 1 | 1699 | COMMIT /* xid=140 */ |
| binlog.000007 | 1699 | Rotate | 1 | 1743 | binlog.000008;pos=4 例如就想恢复到 insert 的那 4 条数据。
Shell > mysqlbinlog --start-position=871 --stop-position=1470 --database=world1 /usr/local/mysql/data/binlog.000007 | mysql -u root -p -v world1实际情况下,找准了 start position 和 stop position,恢复起来都是很简单的事情。
除了可以找 起始的 position 外,还可以找 binlog 文件内容里的起始时间,例如:
Shell > mysqlbinlog --start-datetime="2022-12-30 22:04:50" --stop-datetime="2022-12-30 22:05:01" --database=world1 /usr/local/mysql/data/binlog.000007 | mysql -u root -p -v world1当 MySQL 运行太多的 binlog,可以考虑删除,有两种删除方式:
Mysql > purge binary logs to 'binlog.000007';# 删除比 binlog.000007 创建时间还早的文件Mysql > purge binary logs before '2022-12-30';# 删除该日期之前的所有文件,每个 binlog 的创建日期写入在文件内容的开头
注:由于 binlog 的重要性以及其特殊性,通常情况下,MySQL 的安装位置与其 datadir 分属不同的物理磁盘,最大程度的降低风险。
中继日志(relay log)
中继日志只存在于主从服务器架构的 从服务器上 。
从服务器为了与主服务器 保持一致,要从主服务器读取 binlog 的内容,并且把读取到的信息写入本地的日志文件中(该文件通常位于 datadir 中),这个从服务器上的本地日志文件就称为 中继日志。然后,从服务器读取中继日志的内容并根据中继日志的内容对从服务器上的数据进行更新,完成主从服务器的数据同步。
relay log 的格式与 binlog 的格式差不多,都需要使用 mysqlbinlog 命令工具进行打开。最简单的一主一从如下:
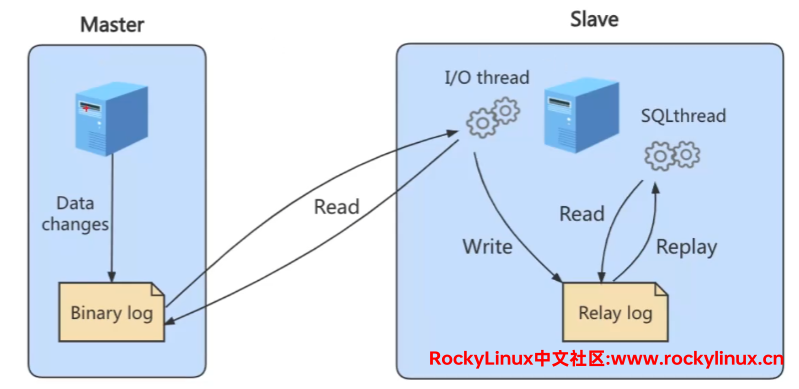
主从同步
主从同步:一台机器硬件所能提供的性能是有上限的,当面对压力很大的请求时,可以考虑搭建多个从 DNS 服务器。DNS服务器是这样,MySQL 服务器也是同样的道理。
MySQL 主从同步的优点有:
- 读写分离。可以通过主从复制的方式同步数据,然后通过读写分离提高并发处理能力。例如 Master 用来专门写数据,其他的 Slave 负责读数据。

- 数据备份。由于通过 Master 将数据同步到 Slave 上,就相当于一种热备份机制做数据的备份。
- HA 高可用。数据同步,本质上就是一种冗余机制,提高了可用性。在运维中,可用性有一定的衡量标准,例如常常听到的两个9(99%),三个九(99.9%)等等之类的,它是指全年都可用的时间,三个9,即全年只允许 (365-365 99.9%) 24 =8.76h 是不可用的(日常维护、系统崩溃等等)。
原理
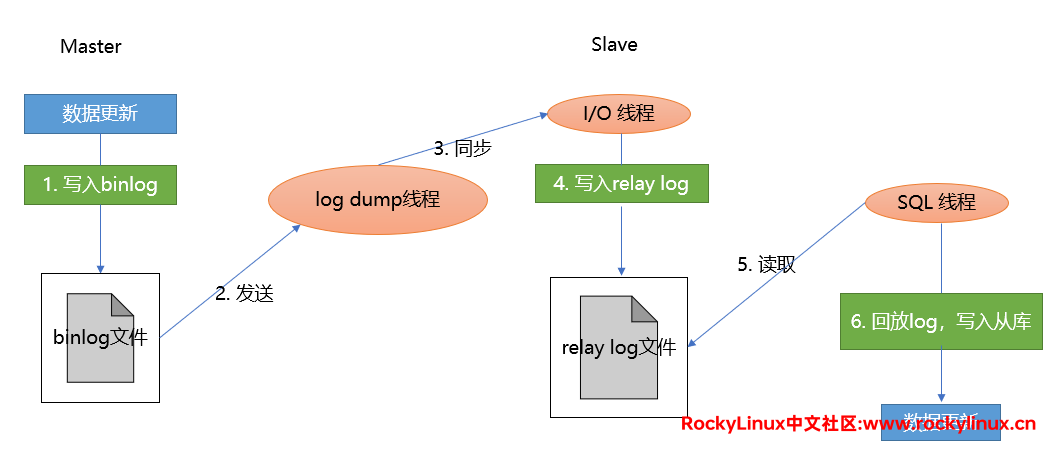
主从同步涉及到三个线程:
- 主服务器的二进制日志转储线程(binlog dump thread) – 当 Master 和 Slave连接时,创建该线程并发送和同步binlog 的数据,binlog dump thread 会在获取数据时加锁,获取数据后释放锁。注意!一个 binlog dump thread 对应一个 Slave。
- 从服务器的 I/O 线程 – 读取来自主服务器的 binlog 更新的部分,并将其拷贝到本地的中继日志中。
- 从服务器的 SQL 线程 – 读取本地的中继日志,执行文件中的事件,更新数据完成同步。
如下图片所示:
原则
- 每个 Slave 只能有一个 Master
- 每个 Slave 只能有唯一的 server-id
- 每个 Master 可以有多个 Slave
基于上面的原则,可以有「一主一从」、「一主多从」等等。
部署简单的一主一从
注:从 8.0.21 开始,不再以 master 和 slave 来区分主从,而是使用 source 和 replica 来替代。
准备工作:
| OS | 主机名 | IP | 版本 | 时间同步 |
|---|---|---|---|---|
| RL 8.7 (Master) | Master | 192.168.100.3/24 | 8.0.30(源代码编译) | chrony |
| RL 8.7 (Slave) | Slave | 10.1.1.5/24 | 8.0.30(源代码编译) | chrony |
主服务器的配置与操作:
Shell(Master) > vim /etc/my.cnf
[mysqld]
…
server-id = 1
log-bin = /usr/local/mysql/data/master-binlog
read-only = 0
binlog-expire-logs-seconds = 2592000
binlog-format = ROW
# 创建账户
Mysql > create user 'mysqlsync'@'%' identified by '1592778';
# 授权访问相关的库与表
Mysql > grant replication slave on *.* to 'mysqlsync'@'%';
Mysql > alter user 'mysqlsync'@'%' identified with mysql_native_password by '1592778'; # 一定要执行这一步,如果不执行,在从服务器上 使用 show slave status\G; 报错,提示——Authentication plugin 'caching_sha2_password' reported error: Authentication requires secure connectio
Mysql > show grants for 'mysqlsync'@'%';Mysql> show master status;
+----------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+----------------------+----------+--------------+------------------+-------------------+
| master-binlog.000004 | 692 | | | |
+----------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)从服务器的配置与操作:
Shell(Slave) > vim /etc/my.cnf
[mysqld]
…
server-id = 2
relay-log = /usr/local/mysql/data/slave-relaylog
# replicate-do-db = test1 # 复制时要指定的库,多个库需要将该参数写多行
replicate-ignore-db = mysql # 复制时要忽略的库,多个库需要将该参数写多行
replicate-ignore-db = sys
replicate-ignore-db = performance_schema
replicate-ignore-db = information_schema开始同步
Mysql > change replication source to
source_host='192.168.100.3',
source_user='mysqlsync',
source_password='1592778',
source_log_file='master-binlog.000004',
source_log_pos=692;
Mysql > start replica; # 如果这一步报错,可使用 reset replica;
# 查看同步的状态。看到这两个线程的状态为 yes,表示同步成功。
Mysql > show replica status\G;
…
Replica_IO_Running: Yes
Replica_SQL_Running: Yes
…注:我们这里的主从同步是单向的,只有主从同步成功的那一刻起,新创建的库与表才会被同步,过往历史的并不会。当然,你可以将主服务器的过往历史数据使用逻辑备份备份出来,并将它们恢复到从服务器中,这样做也是可以的。
其他说明
复制(Replication)是一种将一组数据从一个数据源拷贝到另外一个或多个数据源的备份技术。通常来说,主要分为同步复制和异步复制:
- 异步复制:先将数据的修改或更新写入到 主 中,完成后将数据复制到另外 一个/多个 副本上。
- 同步复制:在 主 中对数据进行修改/变更的同时,数据被复制到另外 一个/多个 副本上,实时的完成数据复制,有点类似于磁盘阵列中的 raid 1。
在《Redis基础篇01 — Redis 基本概述》文章中,我们还比较过两者的区别:
| 同步复制 | 异步复制 | |
|---|---|---|
| 距离 | 当距离较近时,效果更好。更加适合在 LAN 网络中 | 可在较长的距离上工作,只要数据中心之间的网络连接可用。 |
| RPO (Recovery Point Object) | 零 | 15分钟到几个小时 |
| RTO (Recovery Time Object) | 短 | 短 |
| 成本 | 更贵,需要更多的带宽占用或专用硬件 | 相对更加经济 |
| 带宽占用 | 需要更多的带宽并受延迟影响,可受 WAN 网络中断影响(因为实时传输,所以数据的传输不能推迟到以后) | 需要较少带宽且不受延迟影响,不受 WAN 网络中断影响(因为数据可以保存在本地,等待 WAN 网络恢复后进行复制) |
| 数据丢失 | 零 | 可能会丢失最新的数据更新 |
| 性能 | 低 | 高 |
| 使用场景 | 需要实时的恢复且绝对不允许数据丢失 | 不太敏感的数据且允许丢失部分数据 |
同步复制与异步复制并没有谁更加好一说,具体取决于您的业务场景。但是有一个折中的方案,您可以在基础架构中同时使用同步复制和异步复制,比如将同步复制用于 LAN 中的数据传输,而将关键数据通过 WAN 复制到另外一个远程源上。
基于上面我们使用的 MySQL 主从架构,你应该对复制技术有更一步的了解。










