
消息队列概述
消息队列 是分布式系统中不可缺少的组件之一,主要有异步处理、应用解耦、限流削峰的功能。目前广为使用的消息队列有:
- RabbitMQ
- RocketMQ
- Kafka
集群:强调的是计算机的物理形态与统一管理,但有时也强调软件的集群——将同一个软件(或组件或系统)部署在集群环境的各个计算机上,这也被称为集群。
分布式:指的是将一个业务系统拆分成多个子系统(或组件或子业务,业务系统的拆分就类比开发者代码层面的解耦性),它是一种工作方式,这些组件共同协作组成一个复杂的业务系统。
一个好的设计方案是——集群与分布式结合使用,先分布式后集群,具体的实现就是先将业务拆入成多个子系统(或组件或子业务),然后针对每个子系统(或组件或子业务)进行集群化部署。
Redis 从 5.0 版本开始也加入了消息队列的功能,也就是 stream,也是为了抢下一部分的 MQ 中间件市场份额。
Q:什么是消息队列(Message Queue,MQ)?分类?为什么需要它?
一种异步的服务间通信方式。从字面意思理解——即存放消息的队列,目的不是为了存放消息,而是为了解决通信问题。消息指的是传输的数据,如文本、图片、音频、视频等;队列指的是对传输的数据进行排队(一种特殊的线性表),具有 FIFO 特性,这种特性就好像去银行办理业务一样,先到的人肯定先拿号、先办理、先离开,后到的人后办理、后离开。
众所周知,GNU/Linux 有七大文件类型:
- 普通文件类型(包括 纯文本文件(ASCII);二进制文件(binary);数据格式的文件(data);各种压缩文件。第一个属性为 [-] )
- 目录文件(即目录,第一个属性为[d])
- 块设备文件(存储数据以供系统存取的接口设备,简单而言就是硬盘,第一个属性为 [b])
- 字符设备(串行端口的接口设备,例如键盘、鼠标等等。第一个属性为 [c] )
- 套接字文件 (通常用在网络数据连接,可以启动一个程序来监听客户端的请求,客户端就可以通过套接字来进行数据通信。第一个属性为 [s],最常在 /var/run/ 目录中看到这种文件类型 )
- 管道文件 (一种特殊的文件类型,它主要的目的是,解决多个程序同时存取一个文件所造成的错误。FIFO 是first-in-first-out(先进先出)的缩写。第一个属性为 [p] )
- 链接文件(分为软链接(符号链接)和硬链接(物理链接)。软链接类似 Windows 中的快捷方式。第一个属性为 [l])
MQ 通常被划分为两类:
- 点对点消息队列(P2P):一对一的消息传递模型。发送者(生产者)将其中的每个消息给一个接收者(消费者)进行消费。这种模型的特点是高效、可靠、扩展性强。
- 发布/订阅消息队列(Pub/Sub):基于主题的一对多的消息传递模型。这种模型是灵活、扩展性强、支持消息的格式多、解耦能力比点对点更加强。
比如我们在网上购买平台的秒杀商品,这个参与秒杀的商品只有 100 件,但是有 1000 人在抢,这应该怎么处理?在 12306 购买这趟列车的票,只有剩余的 50 张票,但有 200 人在抢票,怎么处理?理想期望的当然是先到先得,但是你不能排除海量用户在同一时间发起请求,虽然可以通过更换硬件设备达到提高性能的目的,但是硬件设备终究是有性能上限的。
以抢购商品为例,假设极端情况下他们都是同一时间点击了抢购按钮。为了解决这种并发访问的问题,有人提出流量疏导,以 100 人为一组进行分批处理,但是那同时抢购的剩余 900 人怎么办?将这些用户的基本数据信息放入一个位置中进行等待,常见的在用户界面出现「正在拼命抢购」或「正在努力抢购」等等提示。这就是消息队列被需要的主要原因——提高并发能力、减轻数据库压力、提高稳定性等。前面提到,分布式系统是需要解耦的,这也就是为什么消息队列在分布式中那么重要。
Redis 中的消息队列
早期的 Redis 其实就具备 FIFO 的排队特性,使用 list 数据类型就能实现。前面文章提到,list 数据类型拥有 有序性 和 可重复性。
# 假设您的消息队列很简单,其实使用 list 数据类型就能实现,也就是点对点消息队列
192.168.100.3:6379> select 8
OK
192.168.100.3:6379[8]> keys *
(empty array)
192.168.100.3:6379[8]> lpush fifo 1 2 3 4 5
(integer) 5
192.168.100.3:6379[8]> lrange fifo 0 -1
1) "5"
2) "4"
3) "3"
4) "2"
5) "1"
# 逐个弹出元素
192.168.100.3:6379[8]> rpop fifo
"1"
192.168.100.3:6379[8]> rpop fifo
"2"
192.168.100.3:6379[8]> rpop fifo
"3"
192.168.100.3:6379[8]> rpop fifo
"4"
192.168.100.3:6379[8]> rpop fifo
"5"
192.168.100.3:6379[8]> keys *
(empty array)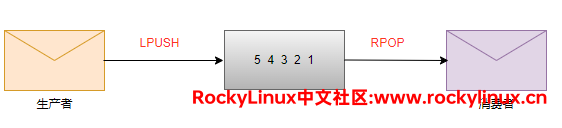
基本结构组成
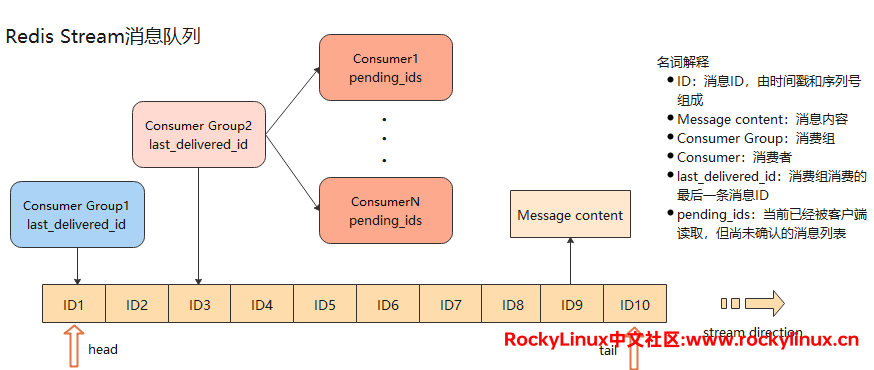
stream 是一个消息链表,每个消息都有唯一的 ID 号和对应内容,将所有的消息串接起来,就有如下图所示的结构,主要由四部分组成:
- 消息:每条消息以追加的方式添加到 stream 队列中
- 生产者:负责向消息队列中生产消息
- 消费者:消费某个信息流。消费者可以属于某个消费组,也可以不属于任何消费组,当不属于任何消费组时,该消费者可以消费消息队列中的任何消息。
-
消费组:一个 stream 队列可以包含多个消费组;每个消费组通过组名称唯一标识;每个消费组的状态都是独立的;每个消费组都可以消费该消息队列的全部消息;一个消费组可以包含多个消费者成员。
- 每个消费组都有一个游标——last_delivered_id,在该组中的任意一个消费者读取了消息后都会使 last_delivered_id 向前移动。
- 消费组中的消费者有一个状态变量 pending_ids(PEL,Pending Entries List),用来记录当前已经被客户端读取但尚未被 ACK 的消息,确保消息被客户端成功消费。
Stream 相关命令
主要划分为两大类:
- 消息队列命令
- 消费组命令
消息队列命令
-
xadd- 添加消息到队列的末端,若队列不存在,则创建队列。要求生成的 ID 要比上一个 ID 大,默认情况下,使用 "*" 自动生成ID,ID 号必须单调递增 -
xtrim- 对 stream 队列修剪至指定长度。- maxlen 参数:允许的最大长度(个数),那些小的 消息ID 会被删除
- minid 参数:允许的最小消息ID,比该 消息ID 小的会被删除
-
xdel- 按照消息ID删除消息,可以指定多个 -
xlen- 获取 stream 队列中的消息个数(消息长度) -
xrange- 获取 stream 队列中的消息列表(ID 从小到大) -
xrevrange- 反向获取消息列表,ID 从大到小 -
xread- 以阻塞或非阻塞方式获取消息列表。- count 参数:最多读取多少个消息
- block 参数:阻塞的毫秒数,设置为 0 表示永远阻塞
消费组命令
xgroup create- 创建消费组xreadgroup group- 读取消费组中的消息xack- 将消息标记为「已处理」xgroup setid- 为消费组设置最后递送消息的 IDxgroup delconsumer- 删除消费者xgroup destroy- 删除消费组xpending- 显示待处理消息的相关信息xclaim- 转移消息的归属权xinfo groups- 查看消费组的信息xinfo stream- 查看队列的信息
特殊符号
在使用相关命令时,会用到一些特殊符号,如下所示:
- - :最小可能出现的 ID
- + :最大可能出现的 ID
- $ :表示只消费新消息
- > :用于
xreadgroup命令,表示还没有发送给消费组中消费者的消息,使用该符号用来更新 last_delivered_id - * :用于
xadd命令,让系统自动生成 ID
消息队列命令的使用演示
xadd 命令
# k1 v1 k2 v2 k3 v3 就是这个该 ID 号的消息
## 命令执行后,输出由两部分组成:UNIX 毫秒时间戳和序列号
192.168.100.3:6379[8]> xadd infostream * k1 v1 k2 v2 k3 v3
"1700665454398-0"
# k4 v4 k5 v5 就是这个该 ID 号的消息
192.168.100.3:6379[8]> xadd infostream * k4 v4 k5 v5
"1700666042451-0"
192.168.100.3:6379[8]> xadd infostream * k6 v6 k7 v7
"1700666252911-0"
192.168.100.3:6379[8]> type infostream
streamxrange 命令
# xrange 命令返回的结果是按照 消息ID 从小到大排序
192.168.100.3:6379[8]> xrange infostream - +
1) 1) "1700665454398-0"
2) 1) "k1"
2) "v1"
3) "k2"
4) "v2"
5) "k3"
6) "v3"
2) 1) "1700666042451-0"
2) 1) "k4"
2) "v4"
3) "k5"
4) "v5"
3) 1) "1700666252911-0"
2) 1) "k6"
2) "v6"
3) "k7"
4) "v7"# 您也可以使用 count 指定消息的个数
192.168.100.3:6379[8]> xrange infostream - + count 2
1) 1) "1700665454398-0"
2) 1) "k1"
2) "v1"
3) "k2"
4) "v2"
5) "k3"
6) "v3"
2) 1) "1700666042451-0"
2) 1) "k4"
2) "v4"
3) "k5"
4) "v5"xrevrange 命令
192.168.100.3:6379[8]> xrevrange infostream + -
1) 1) "1700666252911-0"
2) 1) "k6"
2) "v6"
3) "k7"
4) "v7"
2) 1) "1700666042451-0"
2) 1) "k4"
2) "v4"
3) "k5"
4) "v5"
3) 1) "1700665454398-0"
2) 1) "k1"
2) "v1"
3) "k2"
4) "v2"
5) "k3"
6) "v3"xdel 命令
按照 消息ID 删除消息,可以指定多个。
192.168.100.3:6379[8]> xdel infostream 1700665454398-0
(integer) 1
192.168.100.3:6379[8]> xrange infostream - +
1) 1) "1700666042451-0"
2) 1) "k4"
2) "v4"
3) "k5"
4) "v5"
2) 1) "1700666252911-0"
2) 1) "k6"
2) "v6"
3) "k7"
4) "v7"xlen 命令
获取消息的个数(长度)
192.168.100.3:6379[8]> xlen infostream
(integer) 2xtrim 命令
为方便演示,添加一些消息数据:
192.168.100.3:6379[8]> xadd infostream * newk1 newv1 newk2 newv2
"1700720036423-0"
192.168.100.3:6379[8]> xadd infostream * newk10 newv10 newk20 newv20
"1700720053790-0"
192.168.100.3:6379[8]> xadd infostream * newk11 newv11
"1700720068494-0"
# 共有 5 个消息数据
192.168.100.3:6379[8]> xrange infostream - +
1) 1) "1700666042451-0"
2) 1) "k4"
2) "v4"
3) "k5"
4) "v5"
2) 1) "1700666252911-0"
2) 1) "k6"
2) "v6"
3) "k7"
4) "v7"
3) 1) "1700720036423-0"
2) 1) "newk1"
2) "newv1"
3) "newk2"
4) "newv2"
4) 1) "1700720053790-0"
2) 1) "newk10"
2) "newv10"
3) "newk20"
4) "newv20"
5) 1) "1700720068494-0"
2) 1) "newk11"
2) "newv11"使用 maxlen 参数对消息队列进行裁剪,比如我要截取 3 个。
192.168.100.3:6379[8]> xtrim infostream maxlen = 3
(integer) 2
# 输出如下所示,那些小的消息 ID 就会被删除,只保留消息 ID 大的
192.168.100.3:6379[8]> xrange infostream - +
1) 1) "1700720036423-0"
2) 1) "newk1"
2) "newv1"
3) "newk2"
4) "newv2"
2) 1) "1700720053790-0"
2) 1) "newk10"
2) "newv10"
3) "newk20"
4) "newv20"
3) 1) "1700720068494-0"
2) 1) "newk11"
2) "newv11"也可以使用 minid 参数,比 1700720053790-0 小的会被删除:
192.168.100.3:6379[8]> xtrim infostream minid 1700720053790-0
(integer) 1
192.168.100.3:6379[8]> xrange infostream - +
1) 1) "1700720053790-0"
2) 1) "newk10"
2) "newv10"
3) "newk20"
4) "newv20"
2) 1) "1700720068494-0"
2) 1) "newk11"
2) "newv11"xread 命令
以阻塞或非阻塞方式获取消息列表,默认为非阻塞。
为方便演示,生成新的 key 并添加一些消息:
192.168.100.3:6379[8]> xadd name:stream * name1 frank name2 tom
"1700722232576-0"
192.168.100.3:6379[8]> xadd name:stream * name3 jack
"1700722277610-0"
192.168.100.3:6379[8]> xadd name:stream * name4 django name5 pete
"1700722354829-0"
192.168.100.3:6379[8]> xadd name:stream * name6 herbert
"1700722498920-0"
192.168.100.3:6379[8]> xrange name:stream - +
1) 1) "1700722232576-0"
2) 1) "name1"
2) "frank"
3) "name2"
4) "tom"
2) 1) "1700722277610-0"
2) 1) "name3"
2) "jack"
3) 1) "1700722354829-0"
2) 1) "name4"
2) "django"
3) "name5"
4) "pete"
4) 1) "1700722498920-0"
2) 1) "name6"
2) "herbert非阻塞方式读取2个消息, 0-0 或 00-00 或 000-000 表示从最小的 消息ID 开始读取:
192.168.100.3:6379[8]> xread count 2 streams name:stream 00-00
1) 1) "name:stream"
2) 1) 1) "1700722232576-0"
2) 1) "name1"
2) "frank"
3) "name2"
4) "tom"
2) 1) "1700722277610-0"
2) 1) "name3"
2) "jack"
# 当然,你也可以不指定 count 参数
192.168.100.3:6379[8]> xread streams name:stream 0-0
1) 1) "name:stream"
2) 1) 1) "1700722232576-0"
2) 1) "name1"
2) "frank"
3) "name2"
4) "tom"
2) 1) "1700722277610-0"
2) 1) "name3"
2) "jack"
3) 1) "1700722354829-0"
2) 1) "name4"
2) "django"
3) "name5"
4) "pete"
4) 1) "1700722498920-0"
2) 1) "name6"
2) "herbert"以阻塞方式获取消息列表:
| Session 1(消费者) | Session 2 (生产者) |
|---|---|
| ## 永远阻塞并总是读取最新的消息,等待中 192.168.100.3:6379[8]> xread count 2 block 0 streams name:stream $ |
|
| 192.168.100.3:6379[8]> xadd name:stream * name7 abel "1700725190662-0" |
|
| 1) 1) "name:stream" 2) 1) 1) "1700725190662-0" 2) 1) "name7" 2) "abel" (101.60s) |
消费组命令的使用演示
xgroup create 命令
用来创建消费组,语法为:
# 创建消费组时必须指定 消息ID,有两个特殊的ID
## 0:表示从 stream 队列的 head 开始消费
## $:表示从 stream 队列的 tail 开始消费,这将会忽略队列中已有的消息数据
192.168.100.3:6379[8]> xgroup create name:stream tmpgroup1 $
OK
192.168.100.3:6379[8]> xgroup create name:stream tmpgroup2 0
OK# 你可以使用 xinfo groups 查看目前有哪些 消费组
192.168.100.3:6379[8]> xinfo groups name:stream
1) 1) "name"
2) "tmpgroup1"
3) "consumers"
4) (integer) 0
5) "pending"
6) (integer) 0
7) "last-delivered-id" ←
8) "1700725190662-0" ← 指向尾部最新的消息
9) "entries-read"
10) (nil)
11) "lag"
12) (integer) 0
2) 1) "name"
2) "tmpgroup2"
3) "consumers"
4) (integer) 0
5) "pending"
6) (integer) 0
7) "last-delivered-id"
8) "0-0"
9) "entries-read"
10) (nil)
11) "lag"
12) (integer) 5xreadgroup group 命令
# 再次创建一些消费组,都从 head 开始消费
192.168.100.3:6379[8]> xgroup create name:stream groupa 0
OK
192.168.100.3:6379[8]> xgroup create name:stream groupb 0
OK
192.168.100.3:6379[8]> xgroup create name:stream groupc 0
OK
# 让 groupa 这个消费组里的第一个消费者开始从 head 读取
192.168.100.3:6379[8]> xinfo groups name:stream
1) 1) "name"
2) "groupa"
3) "consumers"
4) (integer) 0
5) "pending"
6) (integer) 0
7) "last-delivered-id" ←
8) "0-0" ← 指向队列的 head
9) "entries-read"
10) (nil)
11) "lag"
12) (integer) 5
...
192.168.100.3:6379[8]> xreadgroup group groupa consumer1 streams name:stream >
1) 1) "name:stream"
2) 1) 1) "1700722232576-0"
2) 1) "name1"
2) "frank"
3) "name2"
4) "tom"
2) 1) "1700722277610-0"
2) 1) "name3"
2) "jack"
3) 1) "1700722354829-0"
2) 1) "name4"
2) "django"
3) "name5"
4) "pete"
4) 1) "1700722498920-0"
2) 1) "name6"
2) "herbert"
5) 1) "1700725190662-0"
2) 1) "name7"
2) "abel"
## 再次查看 last-delivered-id
192.168.100.3:6379[8]> xinfo groups name:stream
1) 1) "name"
2) "groupa"
3) "consumers"
4) (integer) 1
5) "pending"
6) (integer) 5
7) "last-delivered-id"
8) "1700725190662-0"
9) "entries-read"
10) (integer) 5
11) "lag"
12) (integer) 0
...
## 由于 groupa 的 last-delivered-id 已经指向了 tail 的消息,因此此消费组中的其他消费者(比如 consumer2) 已经没有可被读取的消息
192.168.100.3:6379[8]> xreadgroup group groupa consumer2 streams name:stream >
(nil)
## 但是如果换到 groupb,情况则不同,所以可以得出结论——同一消费组中的不同消费者之间是相互竞争的关系
192.168.100.3:6379[8]> xreadgroup group groupb consumer2 streams name:stream >
1) 1) "name:stream"
2) 1) 1) "1700722232576-0"
2) 1) "name1"
2) "frank"
3) "name2"
4) "tom"
2) 1) "1700722277610-0"
2) 1) "name3"
2) "jack"
3) 1) "1700722354829-0"
2) 1) "name4"
2) "django"
3) "name5"
4) "pete"
4) 1) "1700722498920-0"
2) 1) "name6"
2) "herbert"
5) 1) "1700725190662-0"
2) 1) "name7"
2) "abel"
## 当然,你可以使用 count 参数为消费组内每个消费者指定要读的个数,实现消息读取的负载均衡
192.168.100.3:6379[8]> xreadgroup group groupc consumer1 count 2 streams name:stream >
1) 1) "name:stream"
2) 1) 1) "1700722232576-0"
2) 1) "name1"
2) "frank"
3) "name2"
4) "tom"
2) 1) "1700722277610-0"
2) 1) "name3"
2) "jack"
192.168.100.3:6379[8]> xreadgroup group groupc consumer2 count 2 streams name:stream >
1) 1) "name:stream"
2) 1) 1) "1700722354829-0"
2) 1) "name4"
2) "django"
3) "name5"
4) "pete"
2) 1) "1700722498920-0"
2) 1) "name6"
2) "herbert"
## 指针走完
192.168.100.3:6379[8]> xreadgroup group groupc consumer3 count 1 streams name:stream >
1) 1) "name:stream"
2) 1) 1) "1700725190662-0"
2) 1) "name7"
2) "abel"xpending 和 xack 命令
以 groupc 这个消费组为例,此时,该组内的消费者都读取了相应的消息,但还需要一个确认回执机制——ACK,有了这个机制,可增加消息的可靠性(如果没有这个机制,假如 Redis 中途断电或宕机,会导致消息被消费的不可靠性),通常而言,在实际的业务当中,都需要使用 xack 命令来确认消息已经被消费完成。
# 我们可以使用 xpending 来查看特定消费组内已读但是未 ACK 的列表
192.168.100.3:6379[8]> xpending name:stream groupc
1) (integer) 5
2) "1700722232576-0" ← 消费者读取的最小 消息ID
3) "1700725190662-0" ← 消费者读取的最大 消息ID
4) 1) 1) "consumer1"
2) "2"
2) 1) "consumer2"
2) "2"
3) 1) "consumer3"
2) "1"
## 或者查看特定组内特定消费者的读取 消息ID 的情况。用 - + 来指定 消息ID 的范围,数字指定消息的个数
192.168.100.3:6379[8]> xpending name:stream groupc - + 2 consumer2
1) 1) "1700722354829-0"
2) "consumer2"
3) (integer) 6200358
4) (integer) 1
2) 1) "1700722498920-0"
2) "consumer2"
3) (integer) 6200358
4) (integer) 1
## 使用 ACK 机制来确认消息被消费,可以指定多条 消息ID
192.168.100.3:6379[8]> xack name:stream groupc 1700722354829-0 1700722498920-0
(integer) 2
192.168.100.3:6379[8]> xpending name:stream groupc - + 2 consumer2
(empty array)xinfo groups 和 xinfo stream 命令
# 查看队列的一些基本信息。
192.168.100.3:6379[8]> xinfo stream name:stream
1) "length"
2) (integer) 5
3) "radix-tree-keys"
4) (integer) 1
5) "radix-tree-nodes"
6) (integer) 2
7) "last-generated-id"
8) "1700725190662-0"
9) "max-deleted-entry-id"
10) "0-0"
11) "entries-added"
12) (integer) 5
13) "recorded-first-entry-id"
14) "1700722232576-0"
15) "groups"
16) (integer) 5
17) "first-entry"
18) 1) "1700722232576-0"
2) 1) "name1"
2) "frank"
3) "name2"
4) "tom"
19) "last-entry"
20) 1) "1700725190662-0"
2) 1) "name7"
2) "abel"
# 查看队列中的消费组信息
192.168.100.3:6379[8]> xinfo groups name:stream
1) 1) "name"
2) "groupa"
3) "consumers"
4) (integer) 2
5) "pending"
6) (integer) 5
7) "last-delivered-id"
8) "1700725190662-0"
9) "entries-read"
10) (integer) 5
11) "lag"
12) (integer) 0
2) 1) "name"
2) "groupb"
3) "consumers"
4) (integer) 1
5) "pending"
6) (integer) 5
7) "last-delivered-id"
8) "1700725190662-0"
9) "entries-read"
10) (integer) 5
11) "lag"
12) (integer) 0
3) 1) "name"
2) "groupc"
3) "consumers"
4) (integer) 3
5) "pending"
6) (integer) 3
7) "last-delivered-id"
8) "1700725190662-0"
9) "entries-read"
10) (integer) 5
11) "lag"
12) (integer) 0
4) 1) "name"
2) "tmpgroup1"
3) "consumers"
4) (integer) 0
5) "pending"
6) (integer) 0
7) "last-delivered-id"
8) "1700725190662-0"
9) "entries-read"
10) (nil)
11) "lag"
12) (integer) 0
5) 1) "name"
2) "tmpgroup2"
3) "consumers"
4) (integer) 0
5) "pending"
6) (integer) 0
7) "last-delivered-id"
8) "0-0"
9) "entries-read"
10) (nil)
11) "lag"
12) (integer) 5命令输出说明:
- groupa 、 groupb、groupc 因为执行了上面的
xreadgroup group命令示例,因此其 "last-delivered-id" 指向最后一条消息ID记录——1700725190662-0 - groupa 和 groupb 都还有 5 个 "pending" ,表示 5 个消息仅读取但未 ACK
- groupc 因为执行了上面的
xack命令示例,因此其 "pending" 为 3 - tmpgroup1 这个消费组是从队列的 tail 进行消费的,会忽略队列中已有的消息数据,因此您看到的 "pending" 是 0 。
- tmpgroup2 消费组是从队列的 head 进行消费的,但是没有读取任何的消息数据,也就不存在任何消息数据需要 ACK ,因此 "pending" 是 0
xgroup delconsumer 和 xgroup destroy 命令
用来删除队列中的消费组;用来删除某个消费组中的消费者。
# 删除某个消费者后,消费者所拥有的那些已读但未 ACK 的消息记录将不存在
192.168.100.3:6379[8]> xpending name:stream groupc - + 2 consumer3
1) 1) "1700725190662-0"
2) "consumer3"
3) (integer) 3419039
4) (integer) 1
192.168.100.3:6379[8]> xgroup delconsumer name:stream groupc consumer3
(integer) 1
192.168.100.3:6379[8]> xpending name:stream groupc - + 2 consumer3
(empty array)
# 删除消费组
192.168.100.3:6379[8]> xgroup destroy name:stream tmpgroup1
(integer) 1
192.168.100.3:6379[8]> xgroup destroy name:stream tmpgroup2
(integer) 1









