回顾
zset、hash 或 list 都直接或间接使用了 ziplist。当zset、hash 中的元素个数较少且都是短字符串时,Redis 的底层会使用 ziplist 作为其底层的数据。而 list 则使用了 quicklist 这种数据结构。
在配置文件中,有相关的配置参数:
192.168.100.3:6379> config get *ziplist*
1) "list-max-ziplist-size"
2) "-2"
3) "hash-max-ziplist-entries" // hash 包含的最大 field-value 数量
4) "512"
5) "zset-max-ziplist-value" // zset 单个成员的最大长度
6) "64"
7) "hash-max-ziplist-value" // hash 单个 fileld-value 的最大长度
8) "64"
9) "zset-max-ziplist-entries" // zset 包含的最大成员数量
10) "128"以 hash 为例,只要两个条件至少不满足其中的任意一个,则使用 ziplist,否则使用 skiplist;以 zset 为例,只要两个条件至少不满足其中的任意一个,则使用 ziplist,否则使用 skiplist。
从 Redis 7 开始,使用 listpack 这种数据结构替换了 ziplist。
192.168.100.3:6379[5]> config get *listpack*
1) "zset-max-listpack-value" // zset 单个成员的最大长度
2) "64"
3) "list-max-listpack-size"
4) "-2"
5) "set-max-listpack-value"
6) "64"
7) "set-max-listpack-entries"
8) "128"
9) "hash-max-listpack-entries" // hash 包含的最大 field-value 数量
10) "512"
11) "hash-max-listpack-value" // hash 单个 fileld-value 的最大长度
12) "64"
13) "zset-max-listpack-entries" // zset 包含的最大成员数量
14) "128"skiplist 数据结构
skiplist:也称跳跃表或跳表,是一种 随机化 的数据结构,目的是为了提高查询的效率。
有序集合在日常生活中较常见,比如根据成绩分数对学生进行排名、根据得分对游戏玩家进行排名等,而对于有序集合的底层实现,可以是数组、链表、平衡树等。
- 数组不便于元素的插入和删除;
- 链表的查询效率低,需要遍历所有元素;
- 平衡树或红黑树等结构虽然效率高,但实现复杂。
最终,Redis 采用了实现起来简单且效率堪比红黑树的一种数据结构——skiplist
在了解跳跃表之前,需要先了解下有序链表。
有序链表:所有元素都以递增或递减方式有序排列的一种数据结构,每个节点都有指向下个节点的 next 指针,最后一个节点的 next 指针指向 NULL。比如这样的一个递增有序链表:

比如要查询值为 51 的元素,需要从第一个元素开始依次往后查找,顺序为 1 →11→21→31→41→51,需要比较 6 次。不管是删除、插入或修改,其耗时主要表现在查找元素上。于是有人提出,我们可以将有序链表中的部分节点分层,每一层都有一个有序链表。在查找时优先从最高层开始向后查找,当到达了某节点时,如果下一个节点值大于要查询的值或 next 指针指向 NULL,则从当前节点下降一层继续向后查找,这些是否可以提升查找效率?
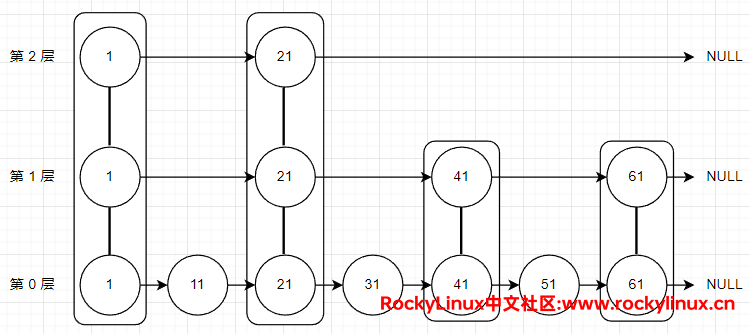
还是查找值为 51 的节点,顺序为:
- 在第 2 层中,1 比 51 小,向后比较;21 比 51 小,向后比较;最终 next 指针指向 NULL,所以从 21 节点开始需要下降一层到第 1 层继续向后比较。
- 在第 1 层中,值为 21 节点的 next 指针指向41,41 比51小,向后比较;61 比要查找的 51 大,则需要从 41 节点下降一层到第 0 层继续向后查找。
- 在第 0 层中,与 51 比较,相等,表示找到值为 51 的节点,查找结束。
需要比较 4 次,分层有序链表就能找到值为 51 的节点,比有序链表的 6 次效率高。当数据量大时,这种查询效率优势会格外地明显。
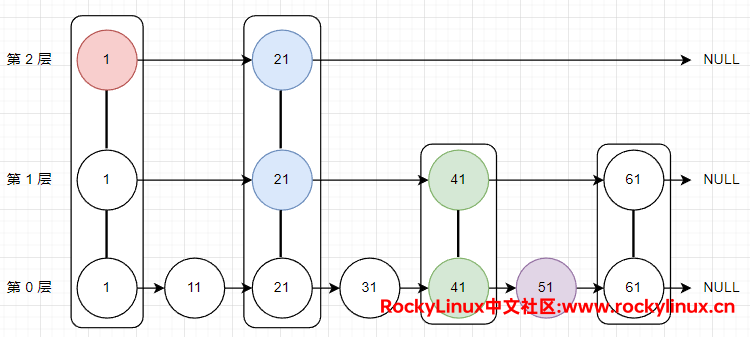
跳跃表的基本思想:通过对有序集合的部分节点分层,由最上层开始依次向后查找,如果本层的下一个节点值大于要查找的值或 next 指针指向NULL,则从当前节点下降一层继续向后查找,以此类推,如果找到,返回节点;否则返回 NULL。在节点比较多时,可以跳过一些节点,查询效率大大提升。
跳跃表这种数据结构的理念其实与 MySQL 索引的 B+TREE 数据结构是差不多的,只不过 Reids 不需要考虑磁盘 I/O 问题。后面我们会有 MySQL 的专题文章来说明。
1. 将数据重新排序
2. 将数据块相邻
所以说什么是索引?完整的说法就是——「提高数据查询效率的一种数据结构,反映在物理磁盘上,将数据重新排序,使物理扇区更加地集中,可最大程度实现顺序读写,减少 I/O的 次数,提高查询的速度。」
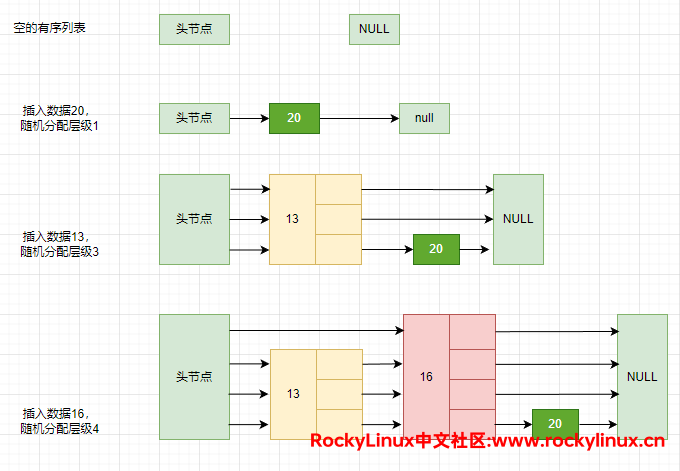
Q:分层有序链表存在什么样的问题?
一旦新插入了节点值或者删除某个节点值,意味着整个分层结构都需要重新调整(比如元素的固定序号需要调整、调整层级等),这样会极大降低 Redis 的性能。Redis 给出的解决办法是 —— 随机性,每一个节点所在的层级是由 Redis 进行随机分配的。Reids 7 当中的层级最小为 1 ,最高为32,层级越高,概率越小。你可以通过阅读源码得到:
Shell > vim /usr/local/src/redis-7.2.1/src/server.h
...
#define ZSKIPLIST_MAXLEVEL 32
...
Shell > vim /usr/local/src/redis-7.2.1/src/t_zset.c
...
int zslRandomLevel(void) {
static const int threshold = ZSKIPLIST_P*RAND_MAX;
int level = 1;
while (random() < threshold)
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
...跳表的结构定义:
Shell > vim /usr/local/src/redis-7.2.1/src/server.h
...
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
...- header:指向跳跃表头节点。
- tail:指向跳跃表尾节点
- length:除头节点以外的节点总和
- level:跳跃表的层级
skiplist 简单的示例图: