
回顾
在前面的文章《Redis基础篇11 — 使用命令(三)对 value 的操作命令》中我们介绍了 hash 数据类型的使用,本篇文章将带您了解 hash 数据类型的底层。
我们说 string 数据类型时,其结构为:
key <---> value而针对 hash 数据类型,它的结构为:
key <---> value
↓
key1-value1(或 field1-value1)
key2-value2(或 field2-value2)
...为了与整体的 key 名称做区分,hash 数据类型中的 key 被称为 field(字段)。请注意!field 和 value 一 一 对应,不允许重复。我们还学习了该数据类型的相关命令:
- hset 和 hsetnx
- hget 和 hmget
- hgetall
- hkeys
- hvales
- hexists
- hdel
- hlen
- hstrlen
- hincrby
- hincrebyfloat
基本概述
hash 的底层由 字典 这种结构来实现,但是 C 语言并没有内置这种数据结构,因此 Redis 需要重新构建自己的数据结构。
字典:又称散列表(hash table)或 哈希表(hash table),是用来存储键值对的一种数据结构,本质上,它是数组的一种拓展。
数组(array):有限个类型相同的对象集合被称为 数组,这些对象被存储在一块连续的内存中。组成数组的各个对象被称为 数组的元素。用于区分数组各个元素的数字编号被称为 下标,从 0 开始记。数组元素的个数被称为 数组长度(length)。
在 C 语言当中,声明一个简单的一维数组的语法为——type arrayName[arraySize],比如:
int data[4]; // 声明长度为4且为整数型的名称为 data 的数组。声明数组就相当于预先分配内存空间。int 一般占用 4 字节,即开辟了 4*4=16 字节的内存空间。
// 给数组元素赋值。0、1、2就是数组的下标
data[0]=200;
data[1]=150;
data[2]=178;
data[3]=1;此时的数组元素被保存在一块连续的内存当中,这些元素(对象)紧紧挨着:
-----------------------------------------
| | | | |
| data[0] | data[1] | data[2] | data[3] |
| | | | |
-----------------------------------------当需要对这个 data 数组进行操作时,C 语言的处理逻辑是通过下标找到其对应的内存地址,然后进行对应的操作。比如我要读取 data[2],通过数组的内存首地址偏移量找到该元素并读取出来,换言之,C 语言中对数组的操作其实就是通过指针和偏移量来实现的,如下说明:
- data 或者 &data[0] 都表示这个数组的起始内存地址
- 内存地址关系:
- &data[0]=data
- &data[1]=data+1
- &data[2]=data+2
- &data[3]=data+3
- 下标、地址、值之间的关系:
- data[0]=*data=200
- data[1]=*(data+1)=150
- data[2]=*(data+2)=178
- data[3]=*(data+3)=1
Redis 是 KV 型 NoSQL,key 可以是字符串、整数型、浮点型等,是不能被直接当成数组的下标来使用的,因此,key 需要进行一些特殊处理来完成和数组元素间的对应关系,这被称为 映射,而完成这种映射的过程被称为 hash。
当字典对指定的 key 进行散列计算后(这通常通过 散列函数 实现,其作用是将任意长度的输入通过散列算法转换为固定类型、固定长度的散列值),可以映射到数组的一个位置,换言之,经过 hash 计算之后,可以把不同类型的 key 转换为唯一的整数型数据。
hash 函数具有的特性或特点:
- 函数应该尽可能简单,以提高转换的速度
- 为了避免空间浪费,处理后的映射应该尽可能地均匀分布
- 相同的输入经过 hash 计算后得出相同输出
- 不同的输入经过 hash 运算后一般得出不同的输出,但也有小概率出现相同的输出。一个好的 hash 算法一定是强调其强随机分布性,否则无法减少 hash冲突 问题。
hash冲突:不同的 key 经过 hash 计算后可能会小概率出现相同的输出,此时会导致 key 最终计算的索引值相同,关联上同一个数组下标,即所谓的 hash 冲突。解决 hash 冲突的方法有很多——比如开放地址法(又称开地址法)、链表地址法(又称拉链法)、再次散列法(又称双散列函数法)等,Redis 采用的是链表地址法来解决 hash 冲突。
开放地址法
基本思想:有冲突时就去寻找下一个空的散列地址,只要散列表的空间足够大散列地址总能找到,并将元素存入。
有一些具体方法来实现这种思想,比如线性探测法、二次探测法、伪随机探测法等等。
链表地址法
基本思想:将相同散列地址的记录串成单链表。
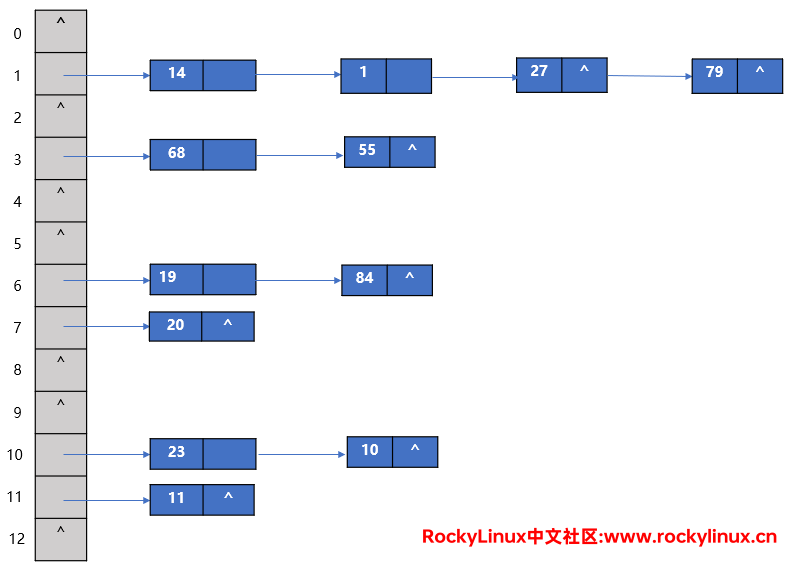
比如有这样的一组数据——{19,14,23,1,68,20,84,27,55,11,10,79},假如我们的散列函数是取模的(取余数),即 hash(key)=key mod 13。这里面的元素 14、1、27、79的余数都是 1 ;68、55余数都是 3 ;19、84余数都是 6 ;23、10余数都是 10。于是就有如下图的结构(左边的0、1、2是下标,可以有13种可能):
Redis 字典源码的基本说明
Shell > vim /usr/local/src/redis-7.2.1/src/dict.hdictEntry
struct dictEntry {
void *key; /* 指向任意类型的 key */
/* 联合体 v 指向实际值的指针 *val */
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; /* 当 hash 冲突时,next 指针指向下一个冲突的元素,形成单链表 */
void *metadata[];
};dictType
/* 字典类型,因为我们会将字典用在各个地方,例如键空间、过期字典等等等 */
typedef struct dictType {
uint64_t (*hashFunction)(const void *key); /* 字典里 hash table 的哈希算法,目前使用的是基于 DJB 实现的字符串哈希算法 */
void *(*keyDup)(dict *d, const void *key); /* 键拷贝 */
void *(*valDup)(dict *d, const void *obj); /* 值拷贝 */
int (*keyCompare)(dict *d, const void *key1, const void *key2); /* 键比较 */
void (*keyDestructor)(dict *d, void *key); /* 键析构 */
void (*valDestructor)(dict *d, void *obj); /* 值析构 */
int (*expandAllowed)(size_t moreMem, double usedRatio); /* 字典里的哈希表是否允许扩容 */
unsigned int no_value:1;
unsigned int keys_are_odd:1;
size_t (*dictEntryMetadataBytes)(dict *d);
size_t (*dictMetadataBytes)(void);
void (*afterReplaceEntry)(dict *d, dictEntry *entry);
} dictType;dict
struct dict {
dictType *type; /* 字典类型,8 Bytes */
dictEntry **ht_table[2]; /* 使用两个哈希表 */
unsigned long ht_used[2];
long rehashidx;
signed char ht_size_exp[2];
void *metadata[];
};









