
回顾
zset、hash 或 list 都直接或间接使用了 ziplist。当zset、hash 中的元素个数较少且都是短字符串时,redis 的底层会使用 ziplist 作为其底层的数据。而 list 则使用了 quicklist 这种数据结构。
关于 list 底层数据结构的实现,随着版本的更替有所不同。
- 早期版本使用 linkedlist(双端列表)和 ziplist(压缩列表)
- 从 Redis 3.2 开启,使用 linkedlist + ziplist 组成的 quicklist。
- 从 Redis 7.0 开始,还是使用 quicklist,只不过将 ziplist 替换为 listpack
我们前面使用了 5 号数据库创建了这样的 KV 数据:
192.168.100.3:6379> select 5
OK
192.168.100.3:6379[5]> keys *
1) "empname:ShangHai"
192.168.100.3:6379[5]> type empname:ShangHai
list
192.168.100.3:6379[5]> object encoding empname:ShangHai
"listpack"
192.168.100.3:6379[5]> lrange empname:ShangHai 0 -1
1) "Leeo"
2) "Jessica"
3) "FrankNewName"
4) "David"Q:你可能好奇,为什么要采用 linkedlist + ziplist(listpack)这种组合的方式呢?
- linkedlist:
- 优点:在实现上比较简单;由于有指针的存在,可以快速找到前一个节点和后一个节点,因此,删除节点、插入节点的操作相对比较简单高效
- 缺点:每个节点都有两个指针(prev 和 next),当拥有很多节点时,内存开销相对更大;当数据量大时,可能会导致节点的地址不连续
- ziplist(listpack):本质上就是一个字节数组,是 Redis 为了节约内存而设计的一种线性数据结构,可以包含多个元素,每个元素可以是一个字节数组或一个整数
- 优点:数组被保存在连续的内存区域当中,能快速访问数组中的元素;内存利用率高
- 缺点:由于是连续的内存区域,因此删除数组元素或插入新的数组元素后,都需要频繁地释放内存以及申请内存
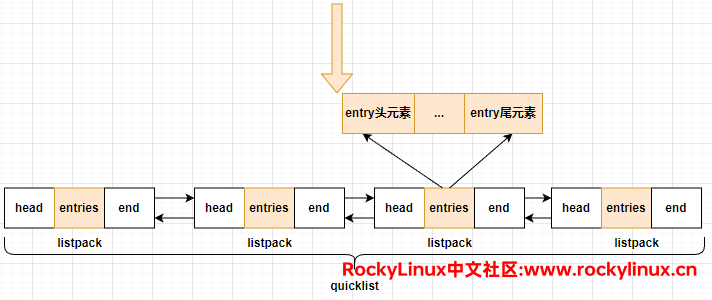
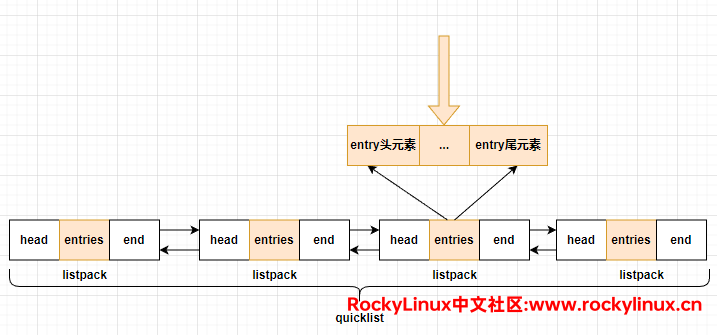
Redis 将这两种数据结构结合,吸取它们的优点,具体的做法是将 linkedlist 按照段切分,每一段使用 ziplist(listpack)来紧凑保存真正的数据元素,多个 ziplist(listpack)之间使用双向指针串接起来,如下所示:

ziplist 的结构(上)和 listpack 的结构(下)如下所示:
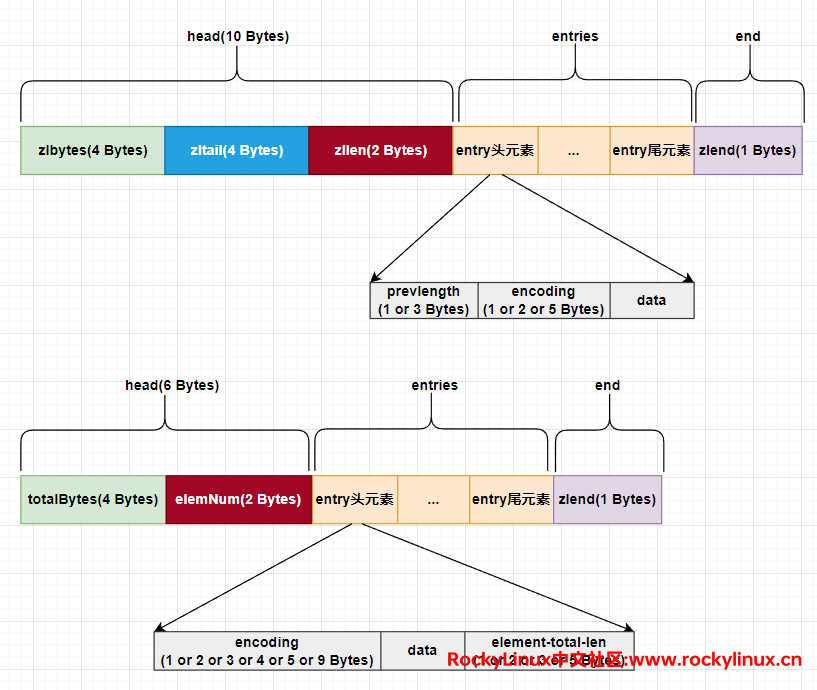
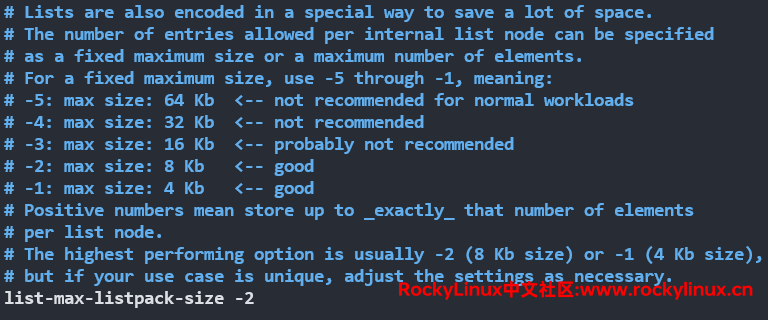
在 quicklist 当中,每个 ziplist(listpack)可以存放的元素上限由配置文件中的 list-max-ziplist-size 或 list-max-listpack-size 参数的值决定,默认情况下,它们的值都为 -2。如注释所述,最好的性能释放通常是 -2 或 -1
查找
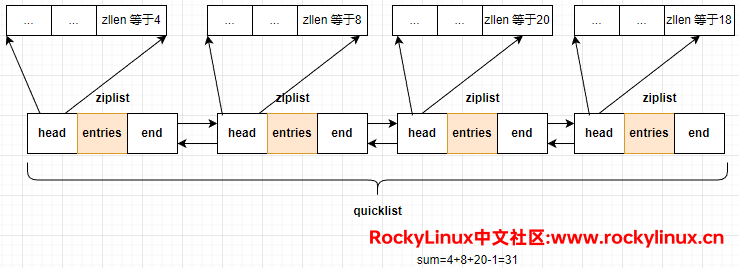
ziplist 结构当中,zllen 记录了 ziplist 的元素个数;listpack 结构当中,elemNum 记录了 listpack 的元素个数。
以 list 数据类型为例,当我们要查找某个元素时,它其实是按照索引(index)下标进行查找的,quicklist 会对每个 ziplist(或 listpack)的 zllen (或 elemNum)做 sum 求和运算,如果要查找元素的索引下标小于等于所求的索引和减1,则确定查找的元素在某个 ziplist(或 listpack)中,遍历之后便可以找到对应的元素。
比如,我要查找索引下标为 15 的元素,我们可以确定元素一定在第三个 ziplist 中。
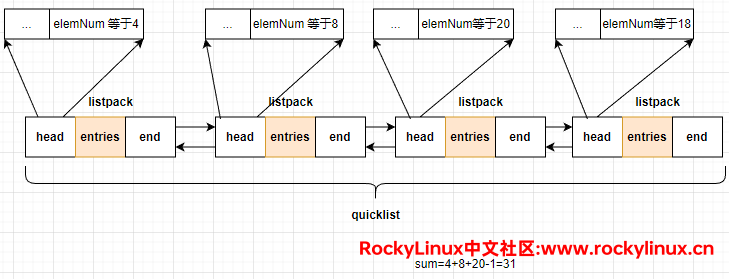
这也适用于 listpack:
插入
ziplist 结构当中,zlbytes 记录了 ziplist 整体数据结构的字节长度,为了方便,ziplist 整体数据结构的字节长度简记为 x;listpack 结构当中,totalBytes 记录了 listpack 整体数据结构的字节长度,为了方便,listpack 整体数据结构的字节长度简记为 y。
假设插入元素的字节大小为 z
第一种情况(x+z <= 8KB 或 y+z <= 8KB)
前面《Redis基础篇06 — 配置文件详解(一)》提到,涉及到内存配置参数值时,不区分大小写,这里的 8Kb=8KB=8*1024Bytes,是 list-max-ziplist-size 或 list-max-listpack-size 参数定义的值。
这种情况则是直接将元素插入到找到的 ziplist(或listpack)中,不需要考虑其他情况。
第二种情况(x+z > 8KB 或 y+z > 8KB)
根据找到的 ziplist(或 listpack)插入位置的不同,又可以划分为不同情况:
-
ziplist(listpack)中元素的起始位置

遇到这种情况,则会判断上一个 ziplist(listpack) 是否还有可容纳的空间。假设上一个 ziplist 的 zlbytes 为 px;上一个 listpack 的 totalBytes 为 py。
- 若 px+z <= 8KB 或 py+z <= 8KB,则直接将元素插入到上一个 ziplist(listpack)的元素尾部
- 若 px+z > 8KB 或 py+z > 8KB,则单独创建一个 ziplist(listpack),并与前后的 ziplist(listpack)串接起来
-
ziplist(listpack)中元素的结束位置
遇到这种情况,则会判断下一个 ziplist(listpack) 是否还有可容纳的空间。假设下一个 ziplist 的 zlbytes 为 nx;下一个 listpack 的 totalBytes 为 ny;
- 若 nx+z <= 8KB 或 ny+z <= 8KB,则直接将元素插入到下一个 ziplist(listpack)的元素起始位置
- 若 nx+z > 8KB 或 ny+z > 8KB,则单独创建一个 ziplist(listpack),并与前后的 ziplist(listpack)串接起来
-
ziplist(listpack)中元素的中间位置
此时需要将找到的这个 ziplist(listpack)拆分为 2 个ziplist(listpack),并与前后的 ziplist(listpack)串接起来。接着,将元素插入到拆分后的前一个 ziplist(listpack)的元素结束位置。
删除
通过索引下标找到元素位于哪一个 ziplist(listpack),直接删除相关元素即可。需要注意!如果这个ziplist(listpack)只有一个元素,一旦将该元素被删除,则这个 ziplist(listpack)也将被删除。










