
回顾
前面提到——「Redis 当中的字符串和 MySQL 当中的字符(char、varchar)以及 JAVA 当中的字符串(string)还不太一样,这涉及到一个东西——简单动态字符串(SDS,simple dynamic string)」
前面还提到:
- string 数据类型中,key 和 value 都是 string 类型
- hash 数据类型中,field 和其 value 都是 string 类型
- list 数据类型中,元素都是 string 类型
- set 数据类型中,成员都是 string 类型
- zset 数据类型中,成员都是 string 类型
请注意!并不是所有 string 类型都是 sds 数据结构,有些也是使用 C 字符串。
sds 目前单独作为一个项目托管在 Github,详情—— https://github.com/antirez/sds
SDS 的结构
虽然 Redis 采用的是标准 C 语言进行开发,但是其并没有采用 C 语言当中的传统字符串,而是自己重新定义了一个,被称为 SDS(Simple Dynamic String)。
需要注意的是,C 语言当中并不存在字符串这种数据类型,而是使用字符 char 并声明初始化一个数组,以 \0 结尾,表示字符串的结束。比如:
char test[6]={'H','e','l','l','o','\0'};
// 或者
char test[]="Hello";"[ ]" 中声明数组的元素个数,数组的下标(或索引)从 0 开始记。在内存当中,其结构是这样的:

以下内容截取自《Redis5设计与源码分析》(陈雷 等著)
Q:如何实现一个扩容方便却二进制安全的字符串呢?什么是二进制安全?
C 语言中,使用 "\0" 表示字符串的结束,如果字符串中本身就有 "\0" 字符,字符串就会被截断,即非二进制安全;如果通过某种机制,保证读写字符串时不会损害其内容,则是二进制安全。
SDS 既然是字符串,那么首先必然是需要一个字符串指针,为了方便上层的接口调用,该结构还需要记录一些统计信息,如当前数据的长度和剩余容量等,于是在 3.2 版本之前,sds.h 文件就有这样的一个结构体:
struct sdshdr {
long len; // 表示 buf 中已用字节的数量,等于 SDS 保存的字符串的长度
long free; // 表示 buf 中剩余可用的字节数量
char buf[]; // 字符数组,即用来保存实际的字符串
};在 64 位系统下,字段 len 和字段 free 各占 4 个字节,紧接着存放字符串。
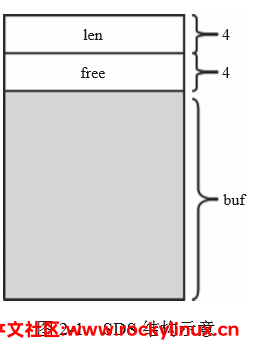
Redis 3.2 之前的 SDS 是这样设计的,这样设计有以下几个优点:
- 有单独的统计变量 len 和 free (它们被称为头部),可以很方便得到字符串长度
- 内容存放在 柔性数组 buf 中,SDS 对上层暴露的指针不是指向结构体 SDS 的指针,而是直接指向柔性数组 buf 的指针
- 由于有长度统计变量 len 的存在,读写字符串时不依赖 "\0" 结束符,这样保证了二进制安全
- buf[ ] 是一个柔性数组,其成员只能被放在结构体的末尾。包含柔性数组成员的结构体,通过 malloc 函数为柔性数组动态分配内存。之所以使用柔性数组存放字符串,其一是因为柔性数组的地址和结构体是连续的,这样查找内存更快(因为不需要额外通过指针找到字符串的位置);其二是可以很方便通过柔性数组的首地址偏移得到结构体首地址,进而方便获取其余变量。
上面就实现了一个最基本的动态字符串,但是还有优化的空间,还应该思考:不同长度的字符串是否有必要占用相同大小的头部?一个 long 占用 4字节,而实际存放在 Redis 当中的字符串往往没那么长,每个字符串长度都用 4 字节存放就有些太浪费了。我们应该考虑三种情况:短字符串,len 和 free 使用 1 字节就够了;长字符串,len 和 free 使用 2 字节或 4字节;更长的字符串,len 和 free 使用 8 字节。
这样确实更加省内存,但是:
- 问题1:如何区分这三种情况?
- 问题2:对于短字符串来说,头部还是太长了。以长度为 1 字节的字符串为例,len 和 free 就一共使用了 2 字节,能不能进一步压缩?
对于问题1,我们考虑增加一个字段 flags 来标识类型,用最小的 1 字节来存储,且把 flags 字段放在柔性数组 buf 之前,这样虽然多了 1 字节,但通过偏移柔性数组的指针即能快速定位 flags,区分类型;对于问题2,len 已经是最小的 1 字节了,再压缩只能考虑使用位(bit)来存储长度了。
综合这两个问题,五种类型(长度 1 字节、2字节、4字节、8字节、小于 1 字节)的 SDS 至少需要使用 3 位来存储类型,1 字节等于 8 位,剩余的 5 位存储长度,可以满足长度小于 32 的短字符串(5 bit最大为 11111,即十机制 16+8+4+2+1=31)。在 3.2 版本之后,可以使用如下结构存储长度小于 32 的短字符串:
struct __attribute__ ((__packed__))sdshdr5 {
unsigned char flags; /* 低3位存储类型,高5位存储长度 */
char buf[]; /* 柔性数组,存放实际内容 */
};在该结构中,flags 占用 1 字节,其低 3 位(bit)表示 type,高 5 位(bit)表示长度,能表示的长度区间为0~31,flags 后面就是字符串内容。
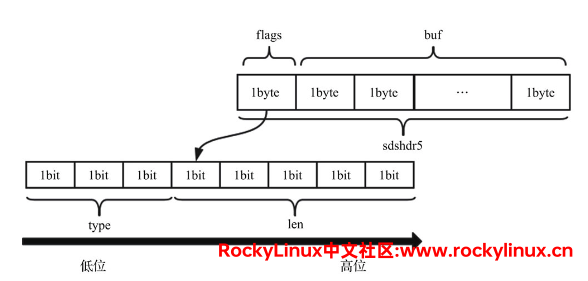
而长度大于 31 的字符串, 1 字节依然存不下。我们按照前面的思路,将 len 和 free 单独存放,也有就了sdshdr8、sdshdr16、sdshdr32、sdshdr64 这四种数据结构,它们在结构上是相同。
在源代码 sds.h 文件中是这样编写的:
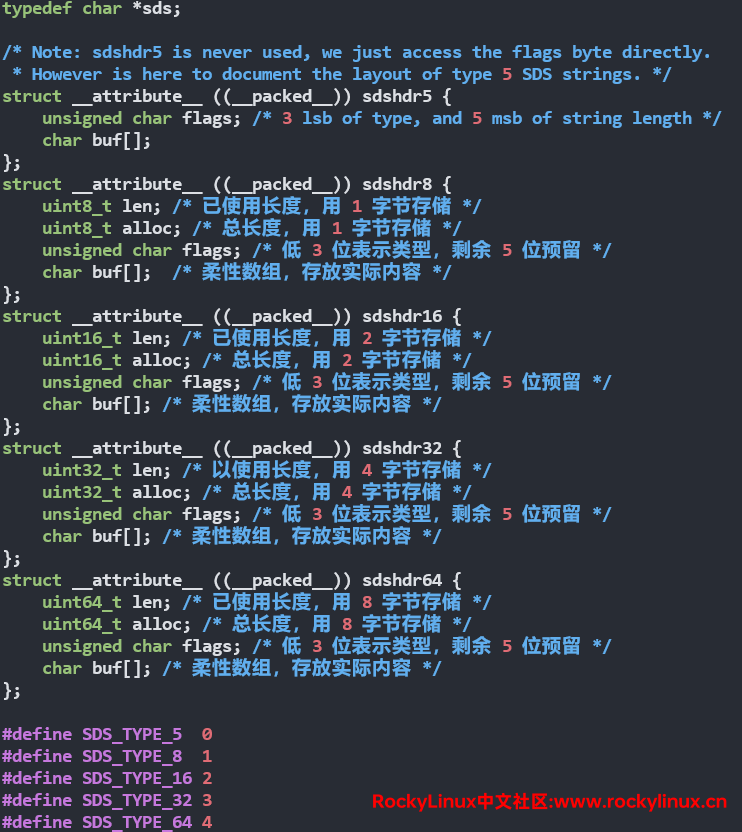
含义:
- len:表示 buf 中已占用字节数,也可以说已使用的长度
- alloc:表示 buf 中已分配字节数,不同于 free,记录的是 buf 分配的总长度
- flags:标识结构体的类型,低 3 位用来标识类型,高 5 位预留
- buf:柔性数组,存储字符串
拿 sdshdr16 来说,其结构如下图所示:
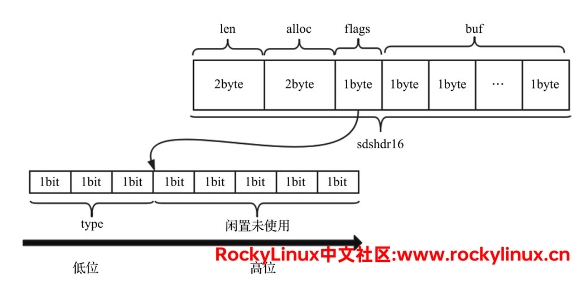
其头部共占用了 5 字节,即len(2字节)+ allow(2字节)+ flags(1字节)。flags的低 3 位(bit)依旧用来表示 type,但剩余的 5 位(bit)不存储长度。
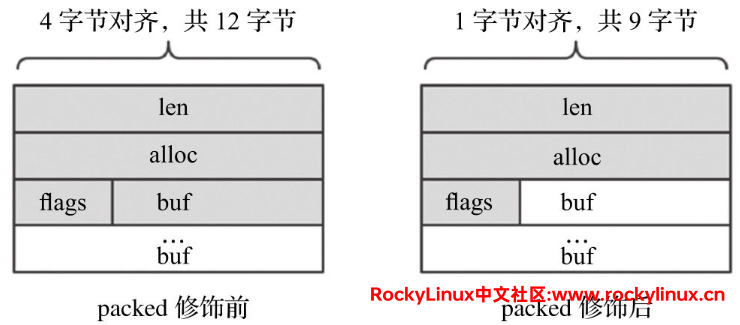
在源代码中的 __attribute__((__packed__)) 需要关注。一般情况下,结构体会按照其所有变量的最小公倍数做字节对齐,而使用 packed 修饰后,结构体会按照 1 字节进行对齐。拿 sdshdr 32 来说,修饰前所有变量的最小公倍数为4字节,则头部占用 12(4*3)字节,修饰后按照 1 字节进行对齐,则头部占用 9(4+4+1) 字节。
这样做的好处:
- 节约内存。例如 sdshdr32 就能节约 3 字节的内存
- SDS返回给上层的不是结构体首地址,而是指向内容的 buf 指针。因为此时按 1 字节对齐,故 SDS 创建成功后,无论是sdshdr8、sdshdr16还是sdshdr32,都能通过 (char*)sh+hdrlen 得到 buf 指针地址(其中 hdrlen 是结构体长度,通过 sizeof 计算得到)。修饰后,无论是sdshdr8、sdshdr16还是sdshdr32,都能通过 buf[-1] 找到 flags,因为此时按 1 字节对齐。若没有 packed 的修饰,还需要对不同结构进行处理,实现上会更加复杂。
与 sds 相关的 C 函数
创建字符串—sdnewlen函数
Redis 会通过 sdsnewlen 函数创建 SDS。在函数中会根据字符串长度选择合适的类型,初始化完成后,返回指向字符串内容的指针,根据字符串长度选择不同的类型:
Shell > vim /usr/local/src/redis-7.2.1/src/sds.c
...
sds _sdsnewlen(const void *init, size_t initlen) {
void *sh;
sds s;
char type = sdsReqType(initlen); //根据字符串长度选择不同的类型
if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8; //SDS_TYPE_5强制转化为SDS_TYPE_8
int hdrlen = sdsHdrSize(type); //计算不同头部所需的长度
unsigned char *fp; /* 指向flags的指针 */
sh = s_malloc(hdrlen+initlen+1); //"+1"是为了结束符'\0'
...
s = (char*)sh+hdrlen; //s 是指向 buf 的指针
fp = ((unsigned char*)s)-1; //s 是柔性数组 buf 的指针,-1 即指向flags
...
s[initlen] = '\0'; //添加末尾的结束符
return s;
}
...创建 sds 的大致流程:首先计算不同类型的头部和初始长度,然后动态分配内存。需要注意以下 3 点:
- 创建空字符串时,SDS_TYPE_5 被强制转换为 SDS_TYPE_8。
- 长度计算时有 "+1" 操作,是为了算上结束符 "\0"。
- 返回值是指向 sds 结构 buf 字段的指针。
释放字符串—sdsfree 方法、sdsclear 方法
该方法通过对 s 的偏移来定位到 SDS 结构体的头部,然后调用 s_free 释放内存
Shell > vim /usr/local/src/redis-7.2.1/src/sds.c
...
void sdsfree(sds s) {
if (s == NULL) return;
s_free((char*)s-sdsHdrSize(s[-1]));
}
...为了优化性能,减少申请内存的开销,SDS 提供了不直接释放内存,而是通过重置统计值达到清空目的的方法——sdsclear。该方法可以仅将 SDS 的 len 归零,而真正存在的 buff 并没有被真正清除,新的数据可以覆盖写入而不用重新申请内存。
Shell > vim /usr/local/src/redis-7.2.1/src/sds.c
...
void sdsclear(sds s) {
sdssetlen(s, 0);
s[0] = '\0';
}
...拼接字符串—sdscatsds函数、sdscatlen 函数
Shell > vim /usr/local/src/redis-7.2.1/src/sds.c
...
sds sdscatsds(sds s, const sds t) {
return sdscatlen(s, t, sdslen(t));
}
...sdscatsds 是暴露给上层的方法,其最终调用的是 sdscatlen 。由于其中可能涉及 SDS 的扩容,sdscatlen 中调用 sdsMakeRoomFor 对带拼接的字符串 s 容量做检查,若无须扩容则直接返回 s ;若需要扩容,则返回扩容好的新字符串 s。函数中的 len、curlen 等长度值是不含结束符的,而拼接时用 memcpy 将两个字符串拼接在一起,指定了相关长度,故该过程保证了二进制安全。最后需要加上结束符。
/* 将指针 t 的内容和指针 s 的内容拼接在一起,该操作是二进制安全的 */
sds sdscatlen(sds s, const void *t, size_t len) {
size_t curlen = sdslen(s);
s = sdsMakeRoomFor(s, len);
if (s == NULL) return NULL;
memcpy(s+curlen, t, len); //直接拼接,保证了二进制安全
sdssetlen(s, curlen+len);
s[curlen+len] = '\0'; //加上结束符
return s;
}sdsMakeRoomFor 的实现过程:
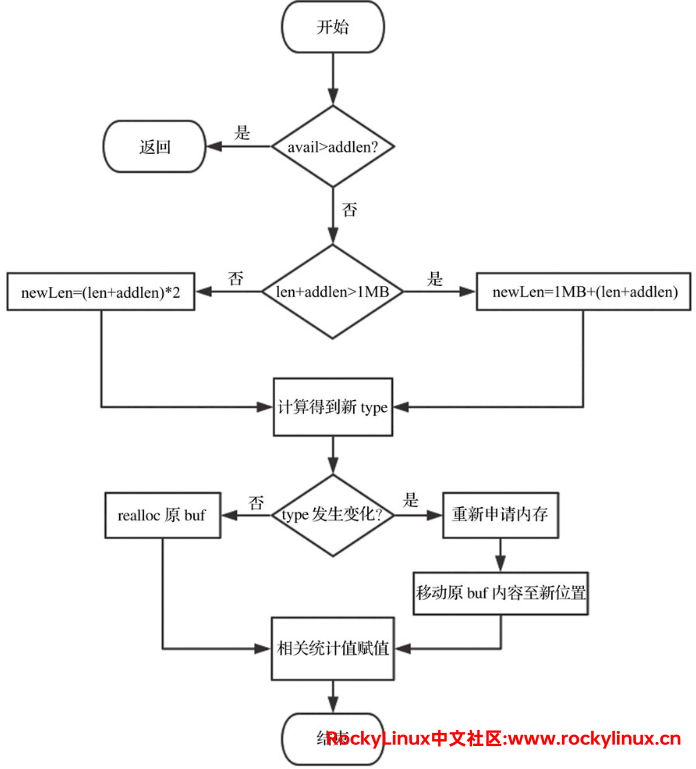
扩容策略:
-
若 sds 中剩余空闲长度 avail 大于新增内容的长度,直接在柔性数组 buf 末尾追加即可,无需扩容,代码如下:
sds _sdsMakeRoomFor(sds s, size_t addlen) { void *sh, *newsh; size_t avail = sdsavail(s); size_t len, newlen; char type, oldtype = s[-1] & SDS_TYPE_MASK; //s[-1]即flags int hdrlen; size_t usable; if (avail >= addlen) return s; //无须扩容,直接返回 ... } -
若 sds 中剩余空间长度 avail 小于或等于新增内容的长度 addlen,则分情况:
- 新增后总长度 len + addlen < 1MB,按照新的总长度的两倍进行扩容((len + addlen)*2)
- 新增后总长度 len + addlen > 1MB,在新的总长度基础上加上 1MB 扩容
sds _sdsMakeRoomFor(sds s, size_t addlen) { ... len = sdslen(s); sh = (char*)s-sdsHdrSize(oldtype); reqlen = newlen = (len+addlen); assert(newlen > len); if (greedy == 1) { if (newlen < SDS_MAX_PREALLOC) // SDS_MAX_PREALLOC 这个宏的值为 1MB newlen *= 2; else newlen += SDS_MAX_PREALLOC; ... } -
最后根据新长度重新选择数据结构并分配空间。若不需要更改数据结构,通过 realloc 扩大柔性数组即可;否则需要申请内存,将原 buf 内容移动到新位置。代码如下:
sds _sdsMakeRoomFor(sds s, size_t addlen) { ... type = sdsReqType(newlen); /* type5的结构不支持扩容,所以这里需要强制转成type8 */ if (type == SDS_TYPE_5) type = SDS_TYPE_8; hdrlen = sdsHdrSize(type); assert(hdrlen + newlen + 1 > reqlen); if (oldtype==type) { /*无须更改类型,通过realloc扩大柔性数组即可,注意这里指向buf的指针s被更新了*/ newsh = s_realloc_usable(sh, hdrlen+newlen+1, &usable); if (newsh == NULL) return NULL; s = (char*)newsh+hdrlen; } else { /* 扩容后数据类型和头部长度发生了变化,此时不再进行realloc操作,而是直接重新开辟内存,拼接完内容后,释放旧指针 */ newsh = s_malloc_usable(hdrlen+newlen+1, &usable); // 按照新长度直接开辟内存 if (newsh == NULL) return NULL; memcpy((char*)newsh+hdrlen, s, len+1); // 将原 buf 内容移动到新位置 s_free(sh); // 释放旧指针 s = (char*)newsh+hdrlen; // 偏移 sds 结构的起始位置,得到字符串起始地址 s[-1] = type; // 为 flags 赋值 sdssetlen(s, len); // 为 len 属性赋值 } usable = usable-hdrlen-1; if (usable > sdsTypeMaxSize(type)) usable = sdsTypeMaxSize(type); sdssetalloc(s, usable); // 为 alloc 属性赋值 return s; }
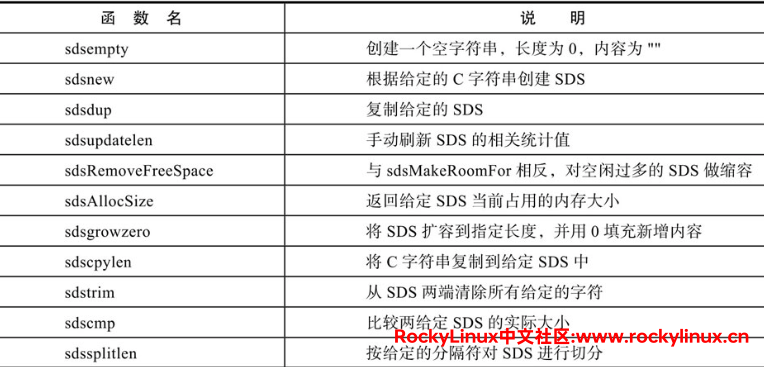
其他函数
总结
Q:为什么 Redis 不使用 C 语言自带的字符串,而是自己封装了一个 SDS ?
sds 的优势:
- 二进制安全。由于有长度统计变量 len 的存在,读写字符串时不依赖 "\0" 结束符,这样保证了二进制安全,这意味着 sds 可以存储二进制数据(音频、视频、图片),但是 C 语言的字符串做不到。
- 预分配机制,当超过了预分配的空间时,sds 可以自动地动态扩容,避免内存溢出问题;
- 高效的字符串操作。SDS 内部有相当多对字符串的操作函数
- 高效的内存管理与优化,避免频繁的释放内存与申请内存










